Mohsen Koohi Esfahani
Supervisors: Hans Vandierendonck and Peter Kilpatrick
Thesis in PDF format
Thesis on QUB Pure Portal
Graph algorithms find several usages in industry, science, humanities, and technology. The fast-growing size of graph datasets in the context of the processing model of the current hardware has resulted in different bottlenecks such as memory locality, work-efficiency, and load-balance that degrade the performance. To tackle these limitations, high-performance computing considers different aspects of the execution in order to design optimized algorithms through efficient usage of hardware resources.
The main idea in this thesis is to analyze the structure of graphs to exploit special features that are key to introduce new graph algorithms with optimized performance.
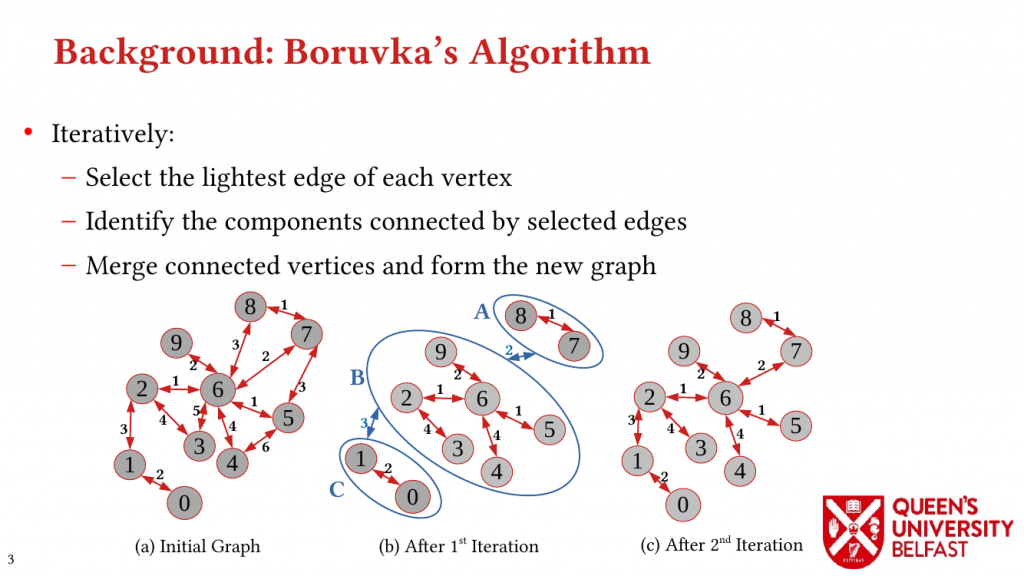
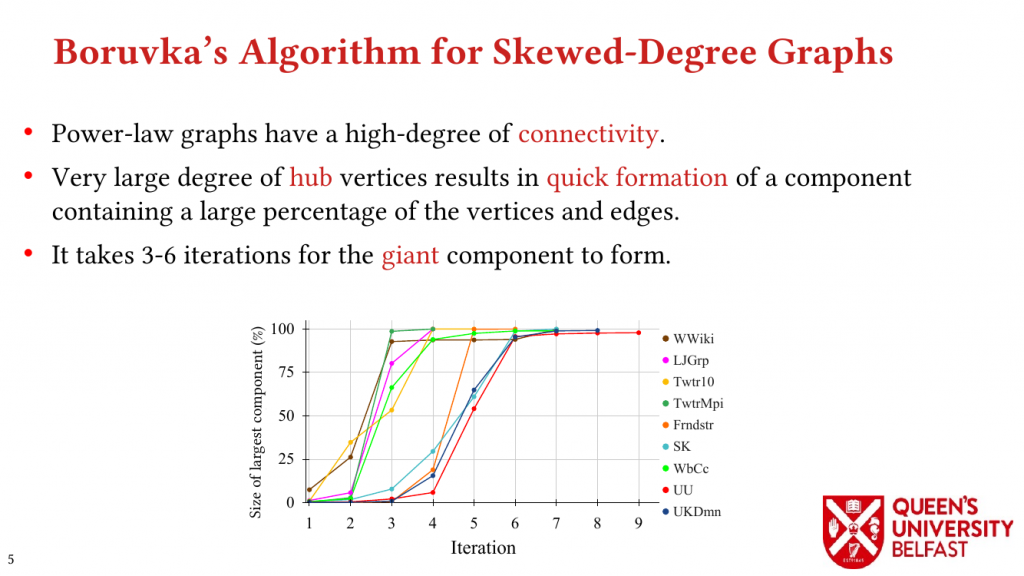
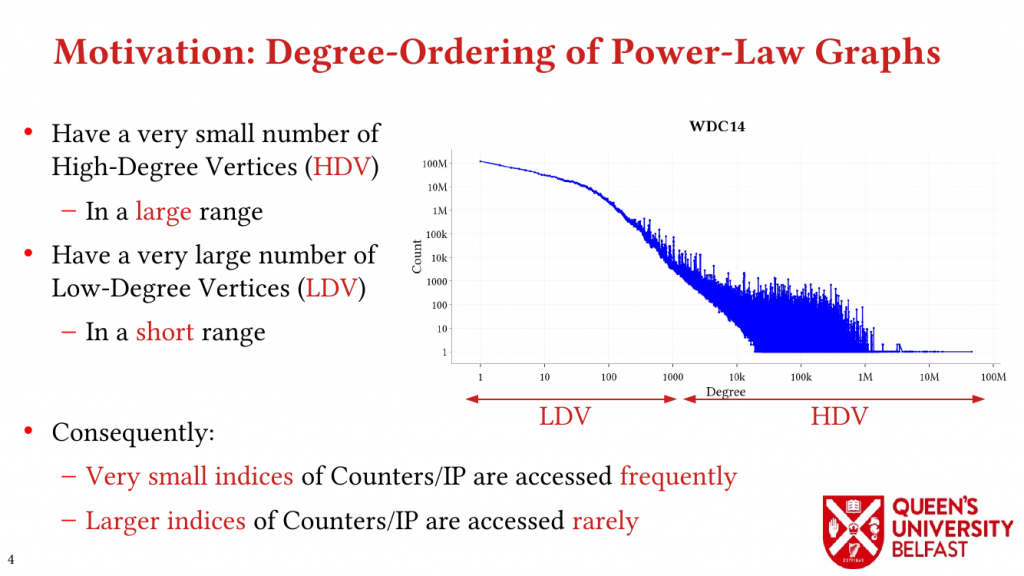
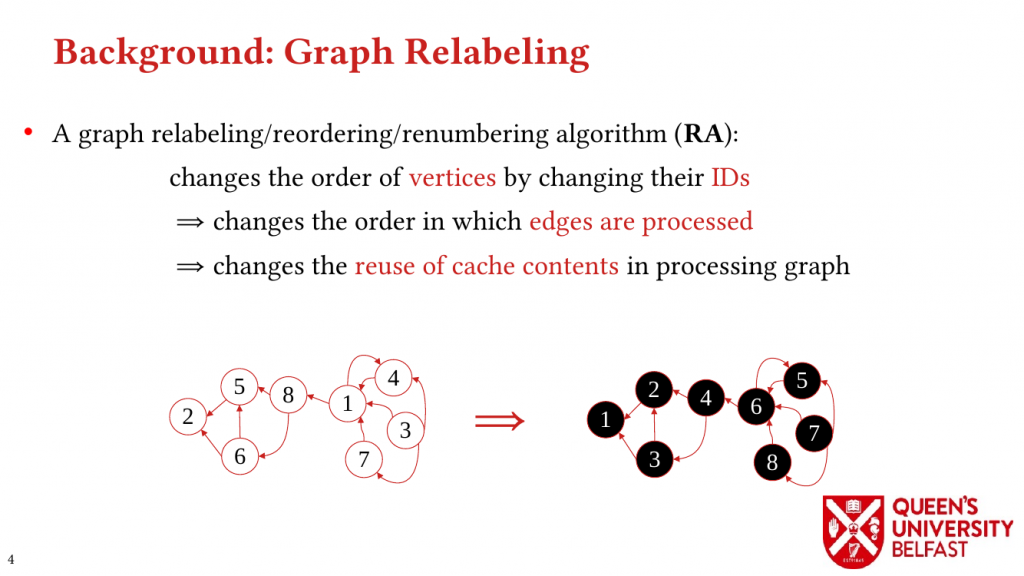
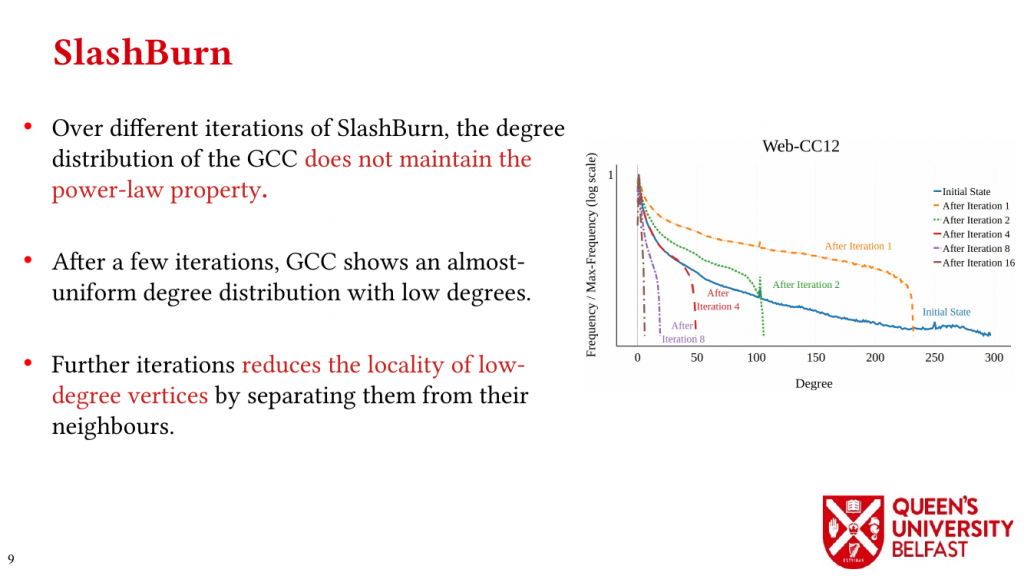
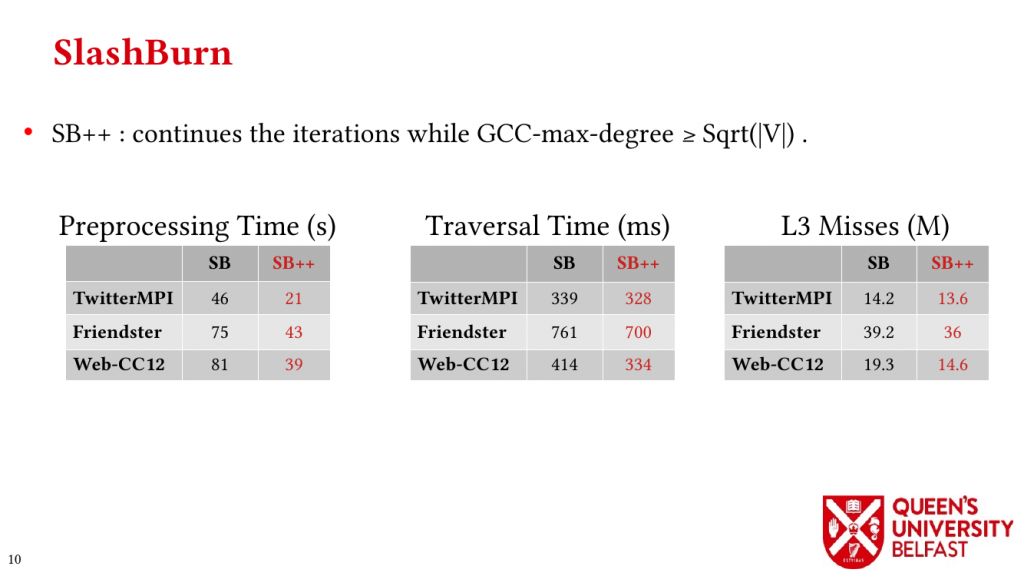
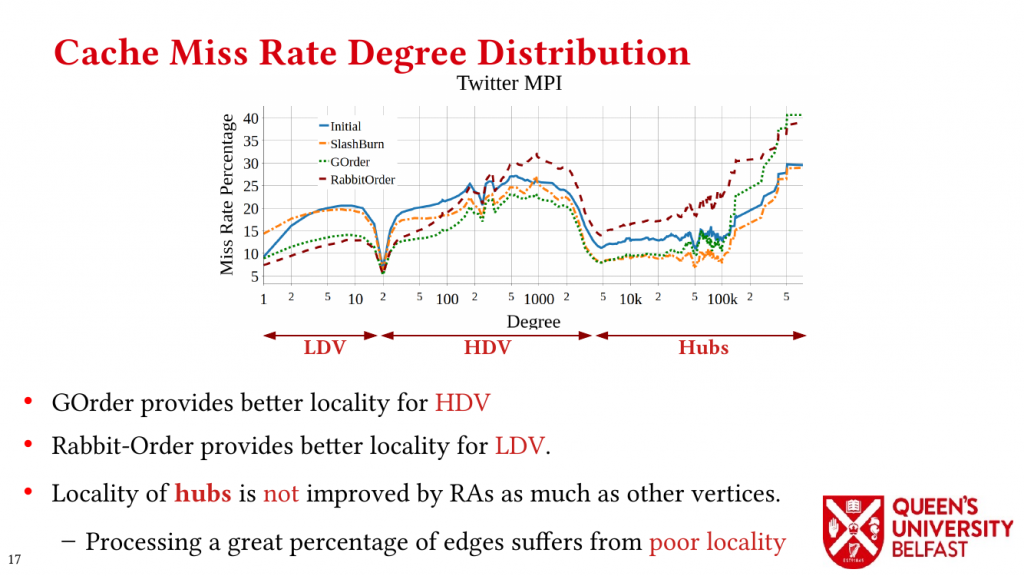
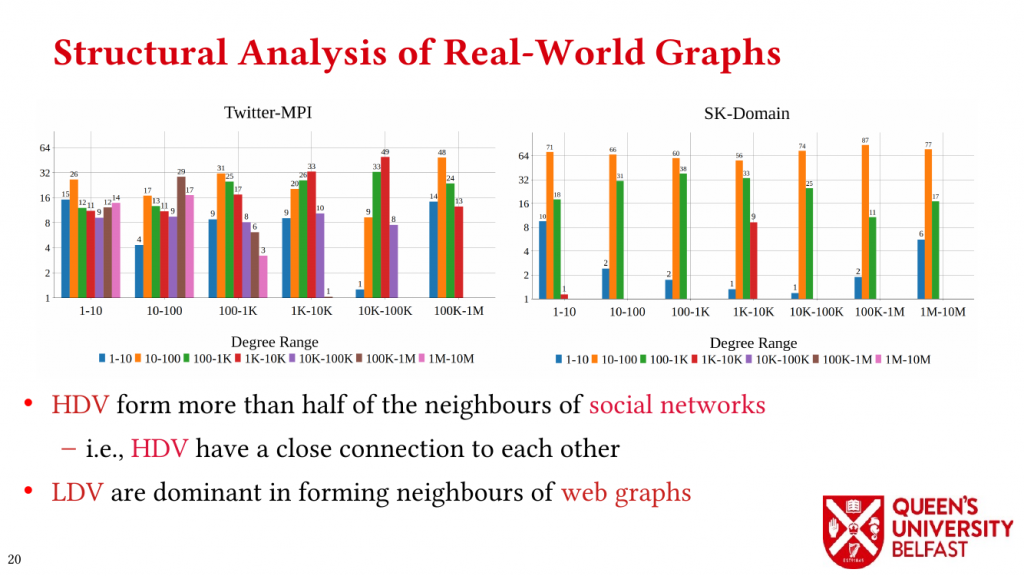
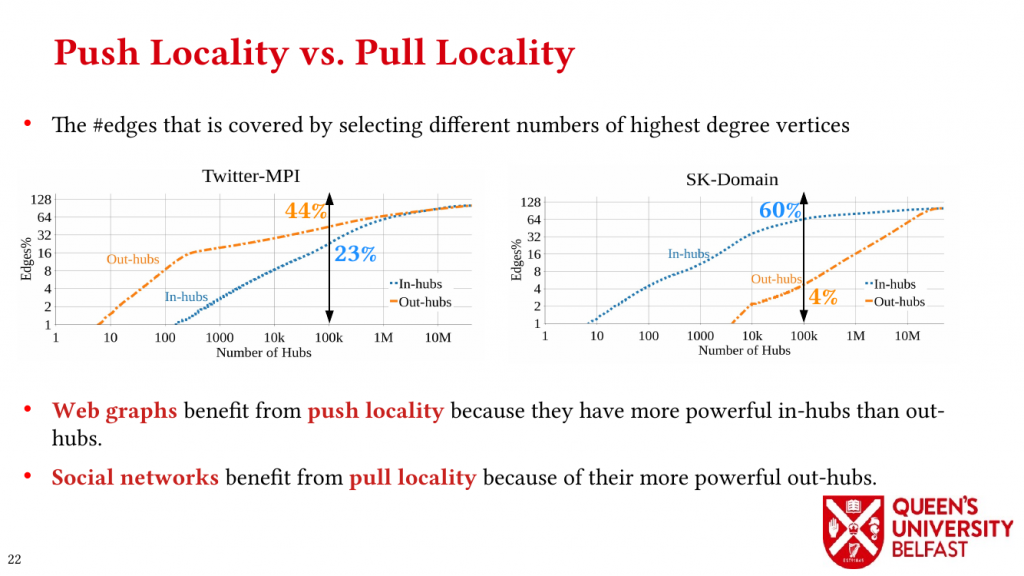
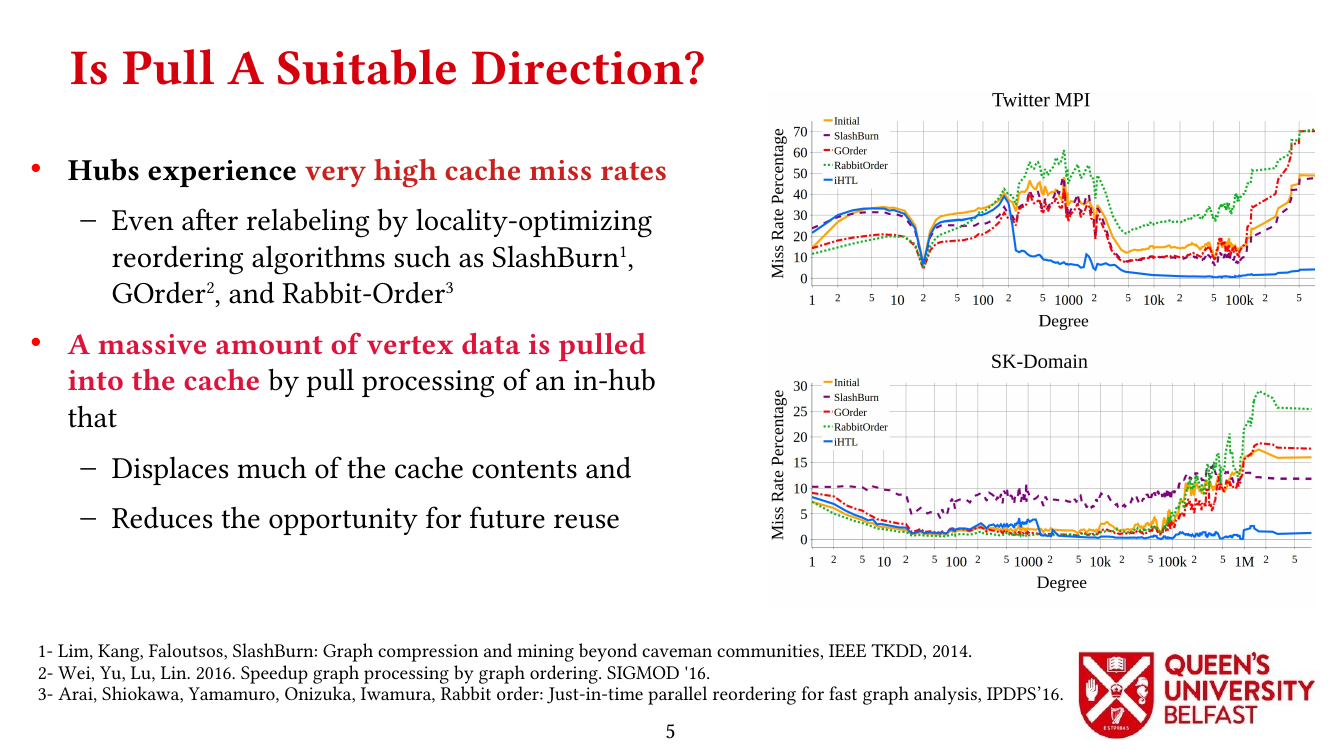
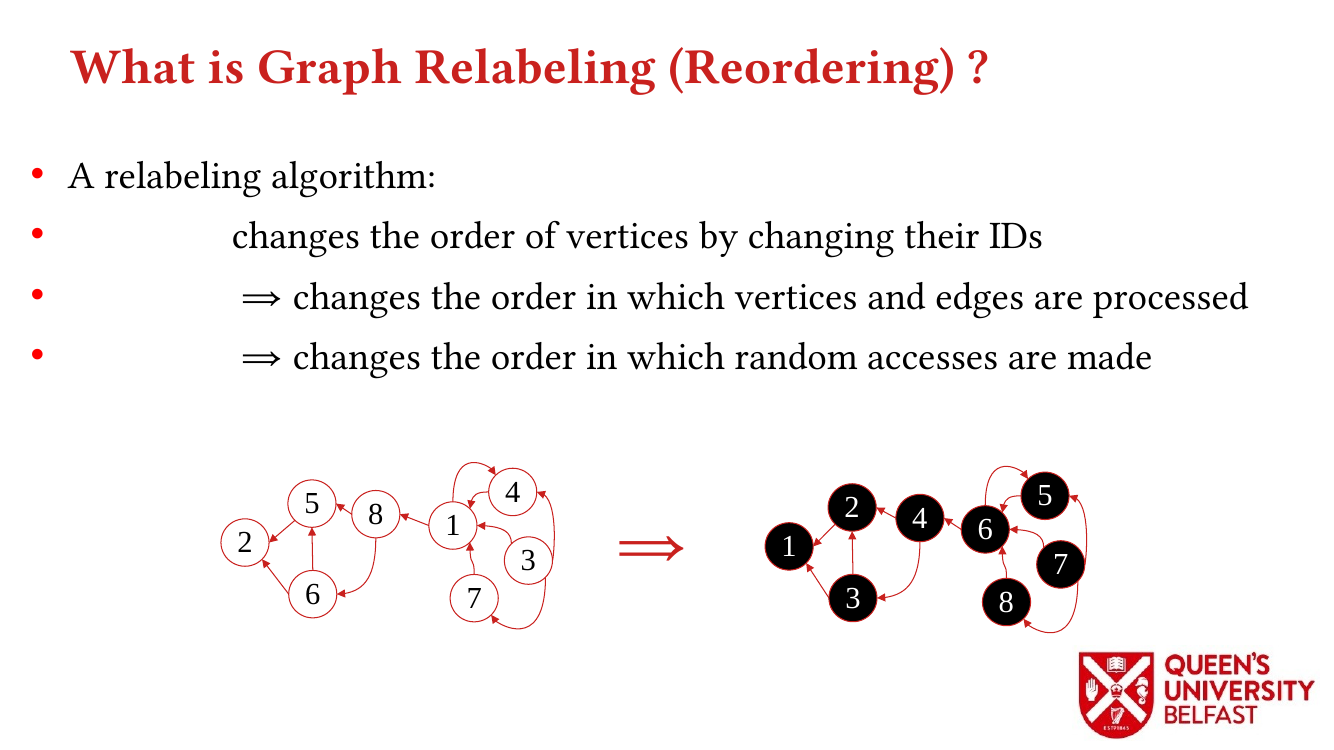
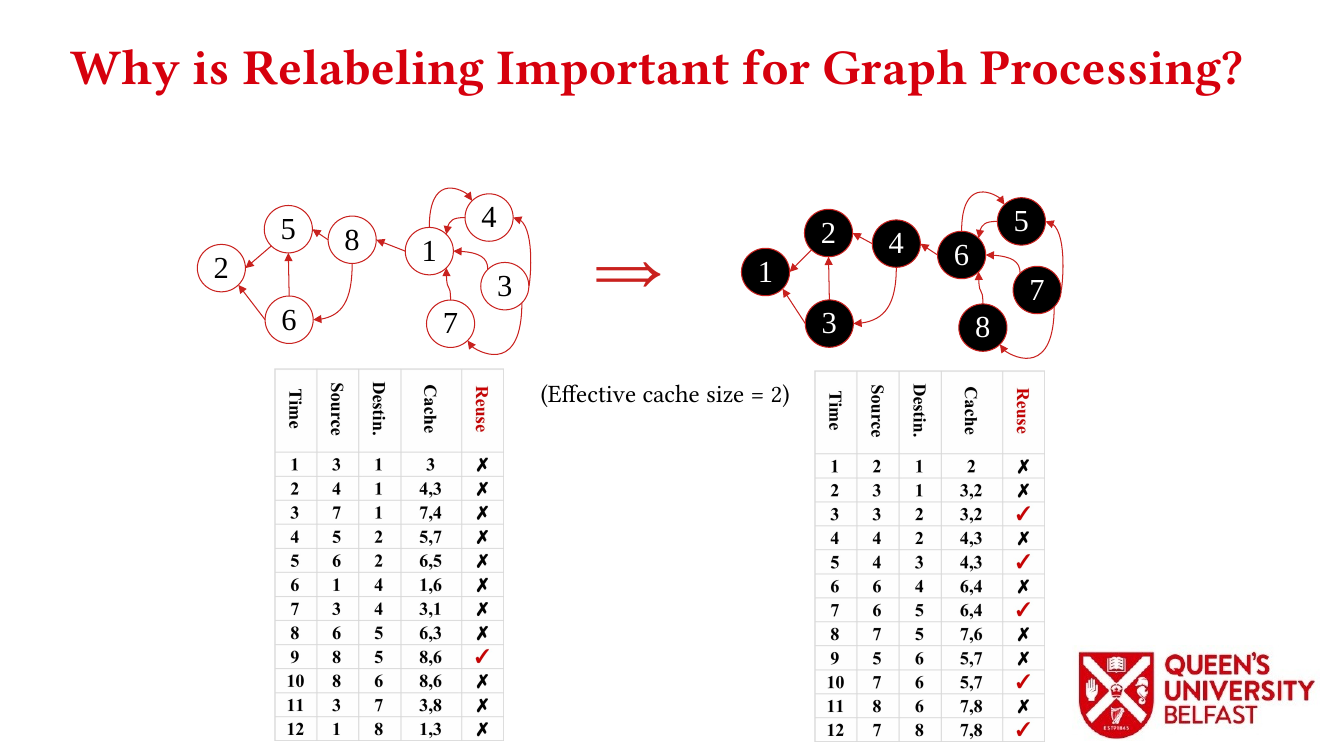
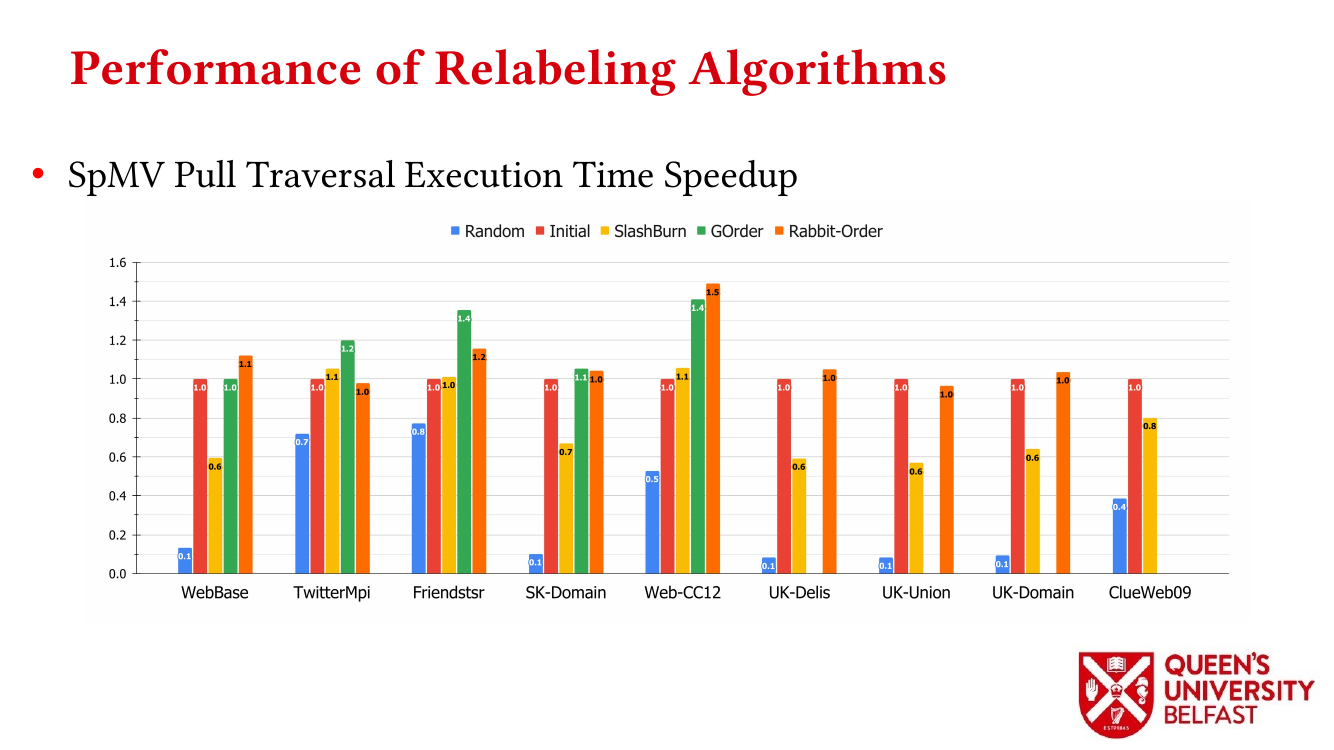
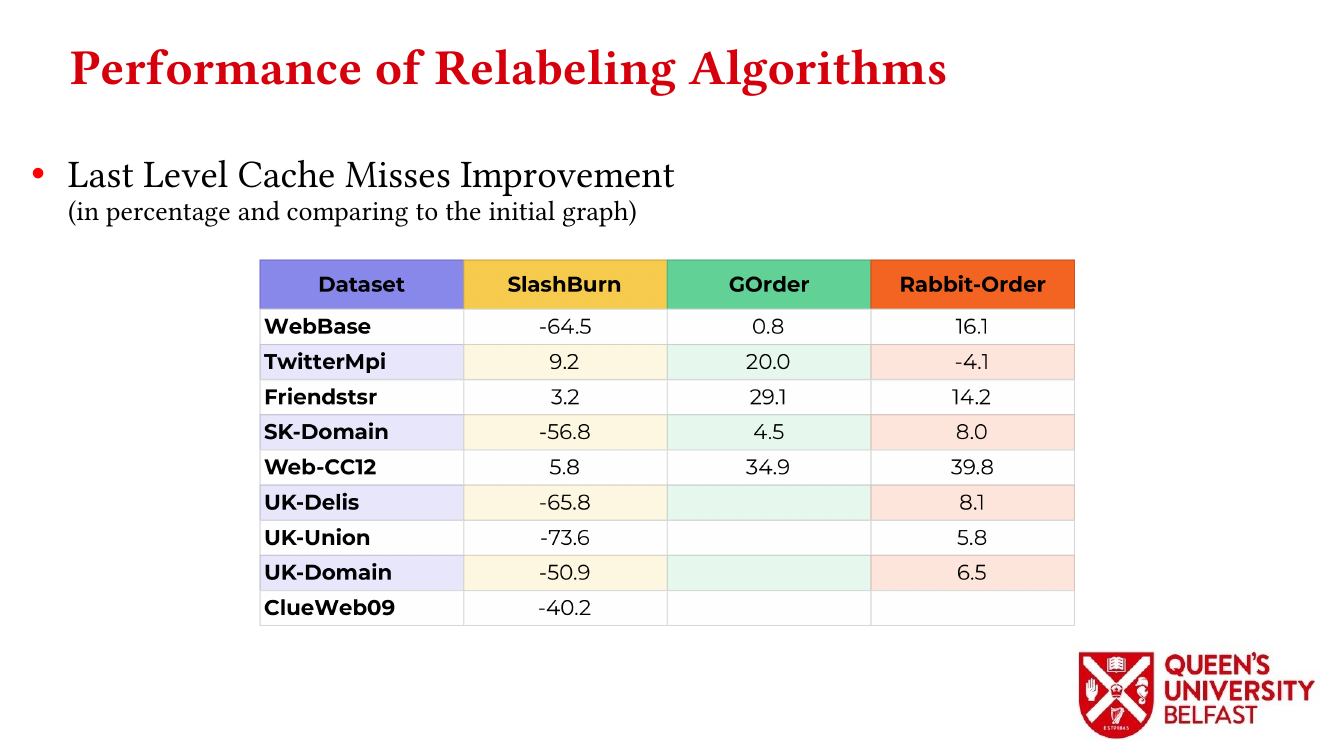
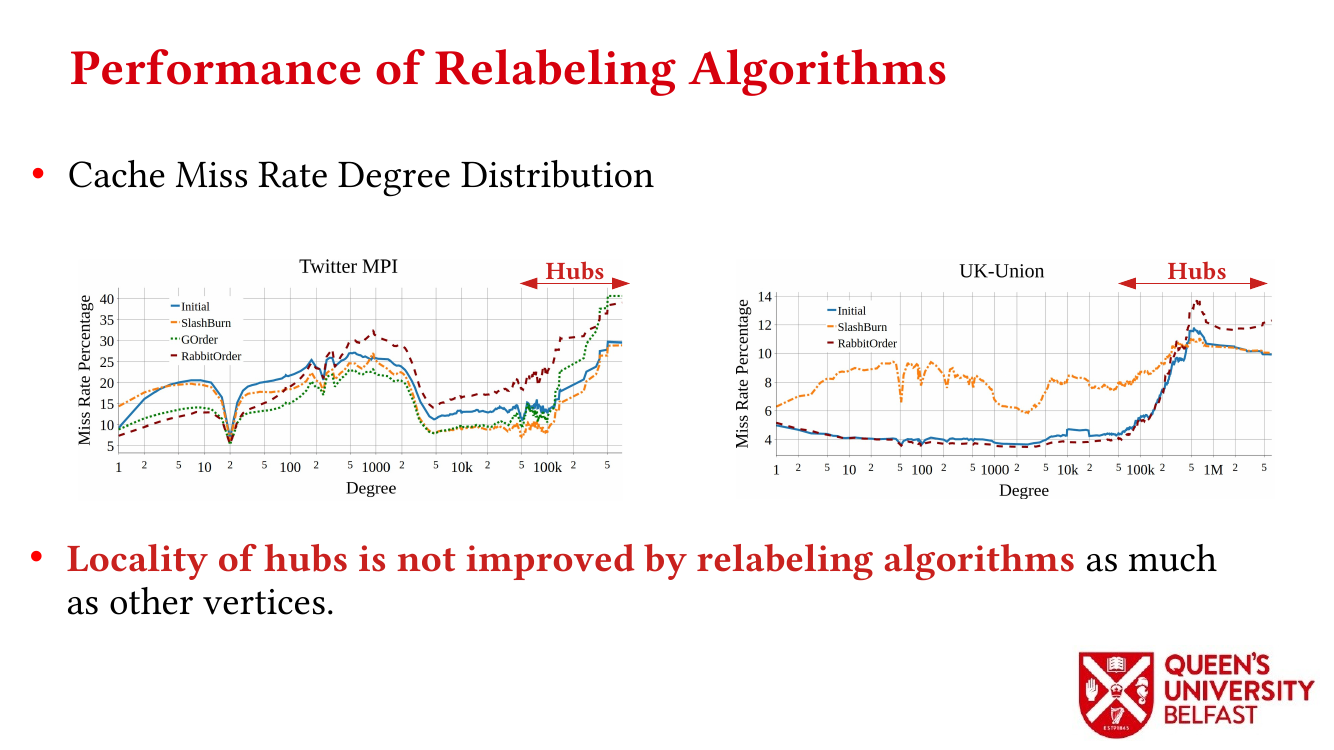
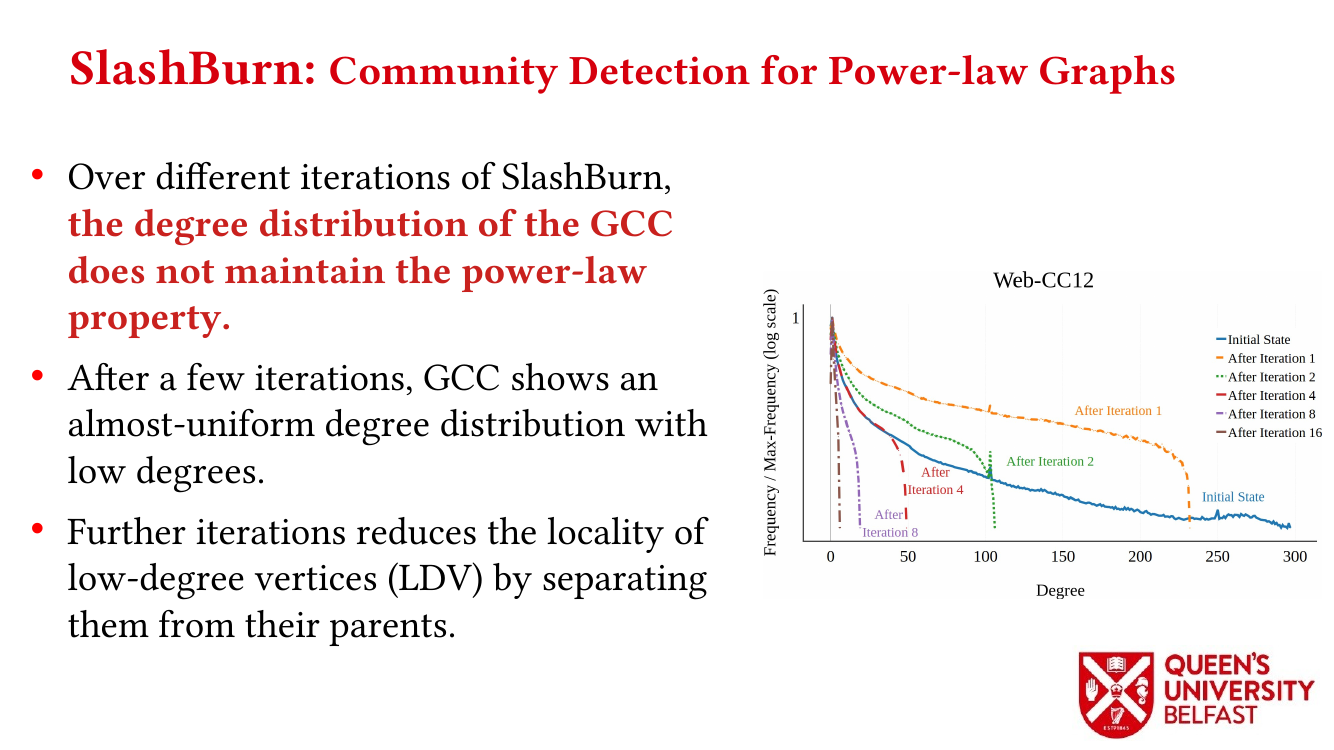
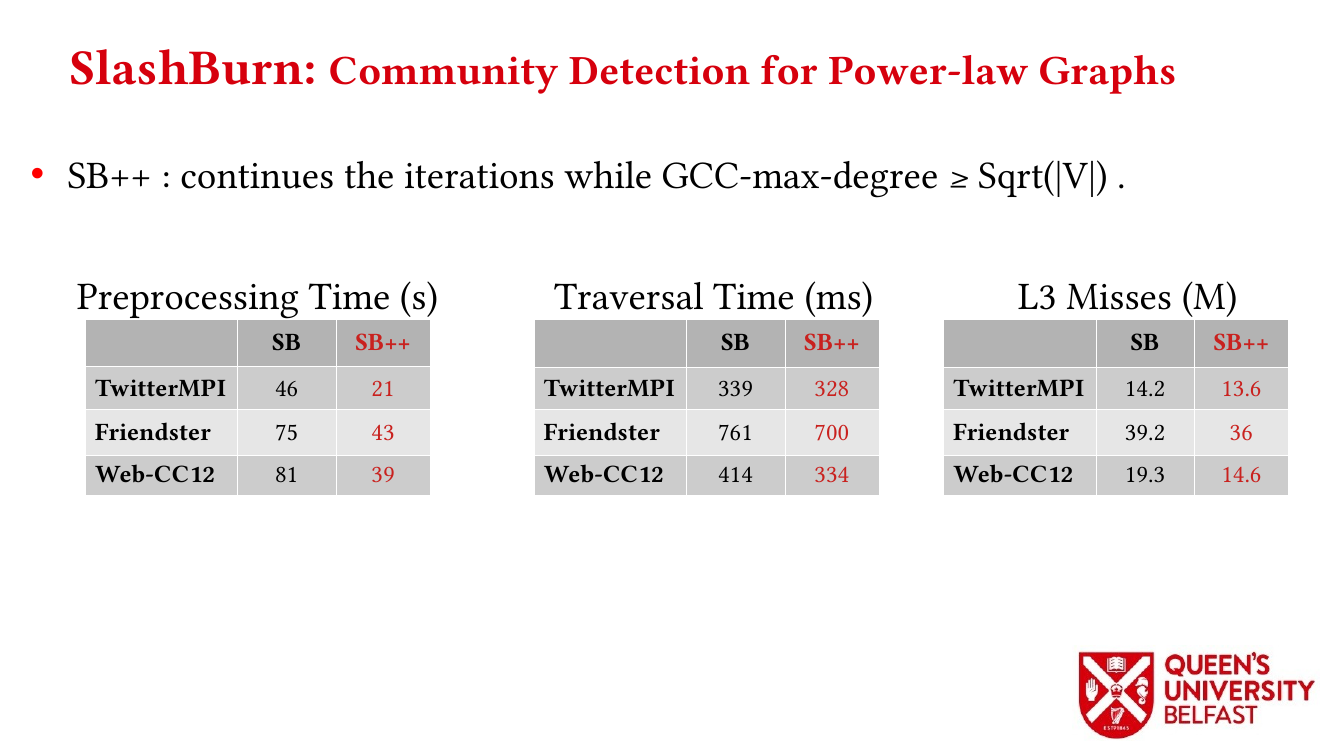
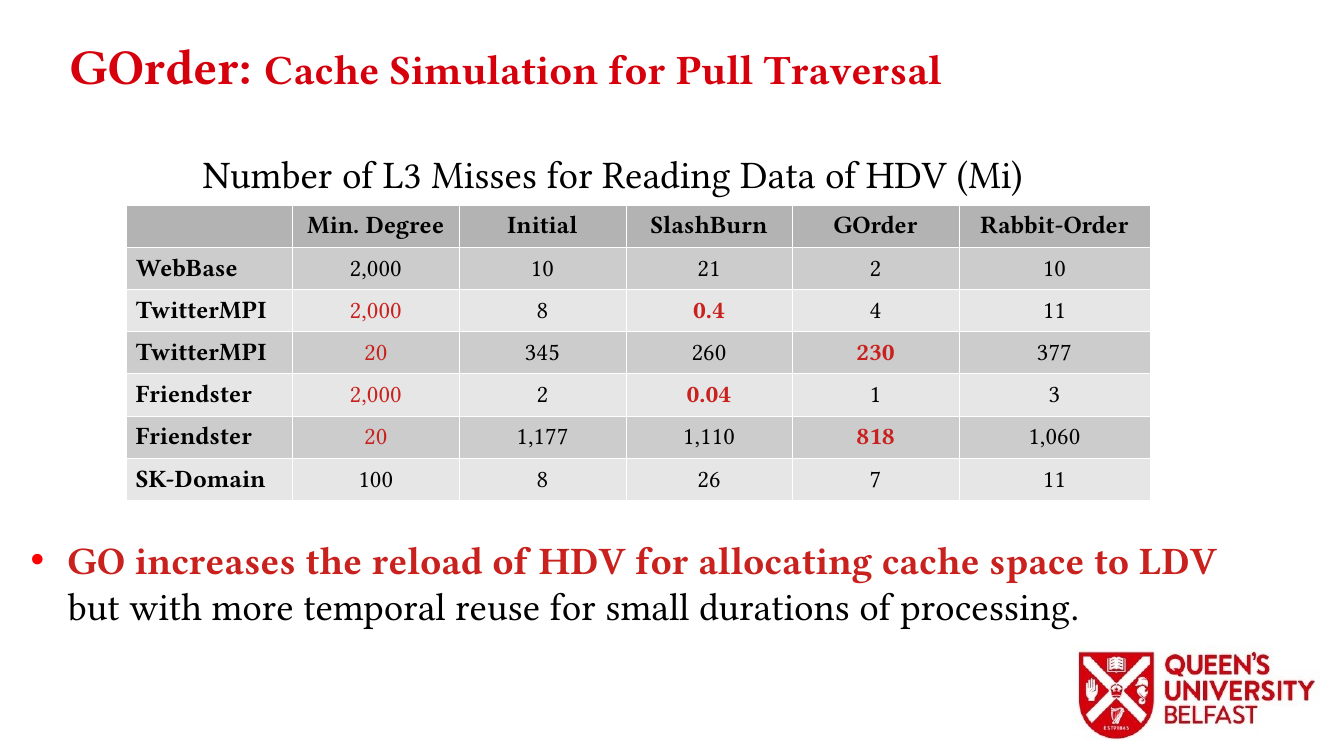
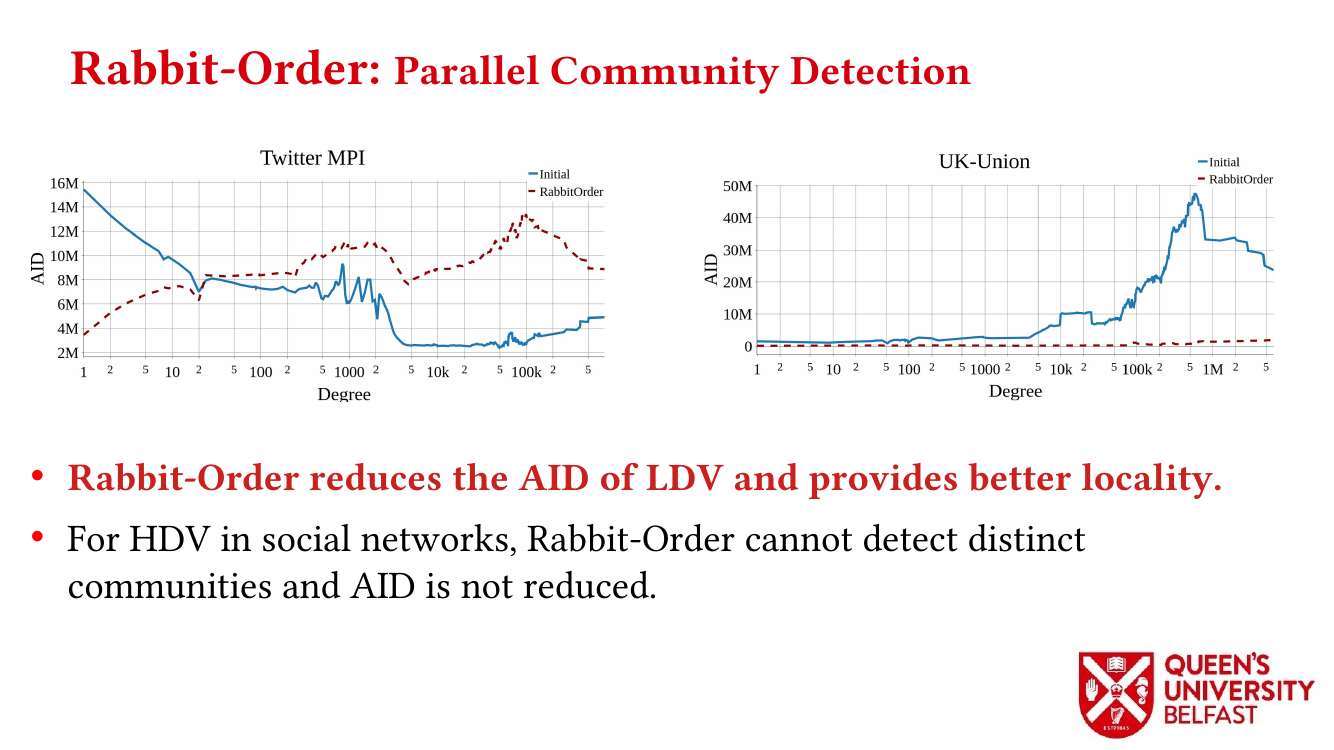
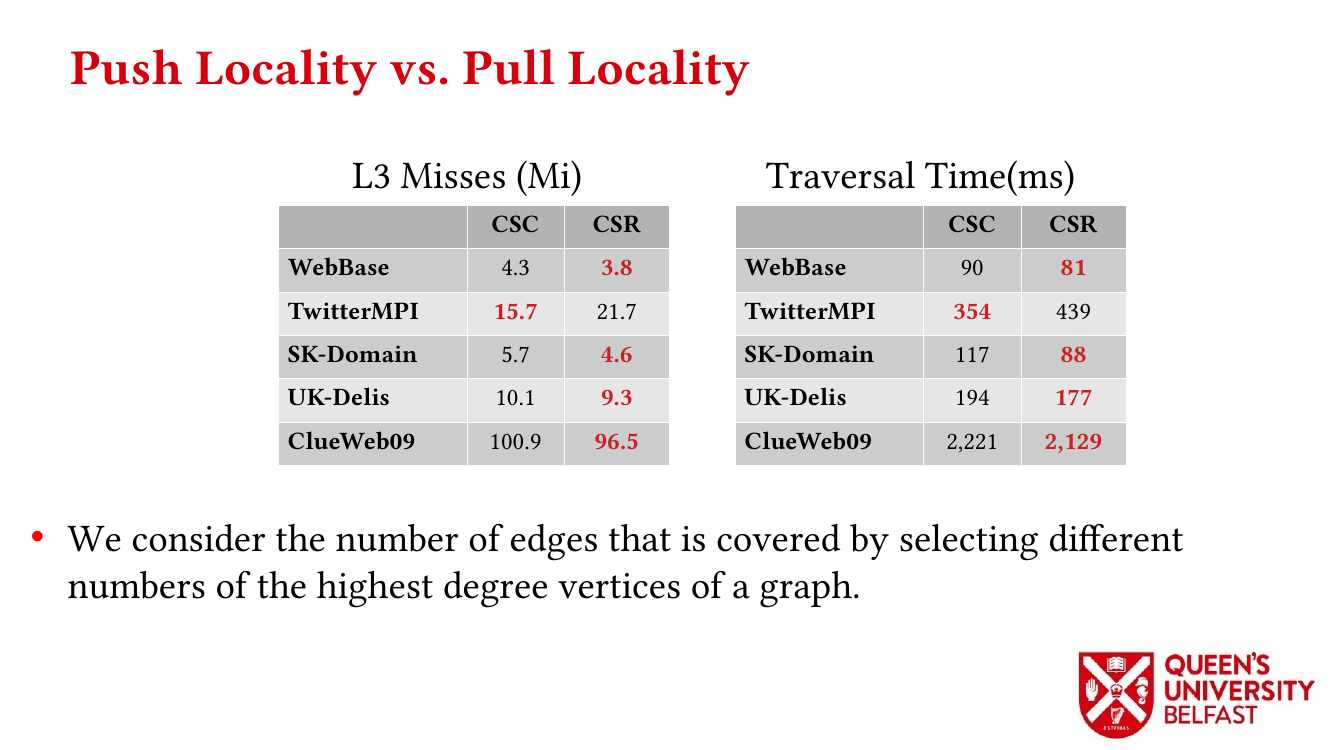
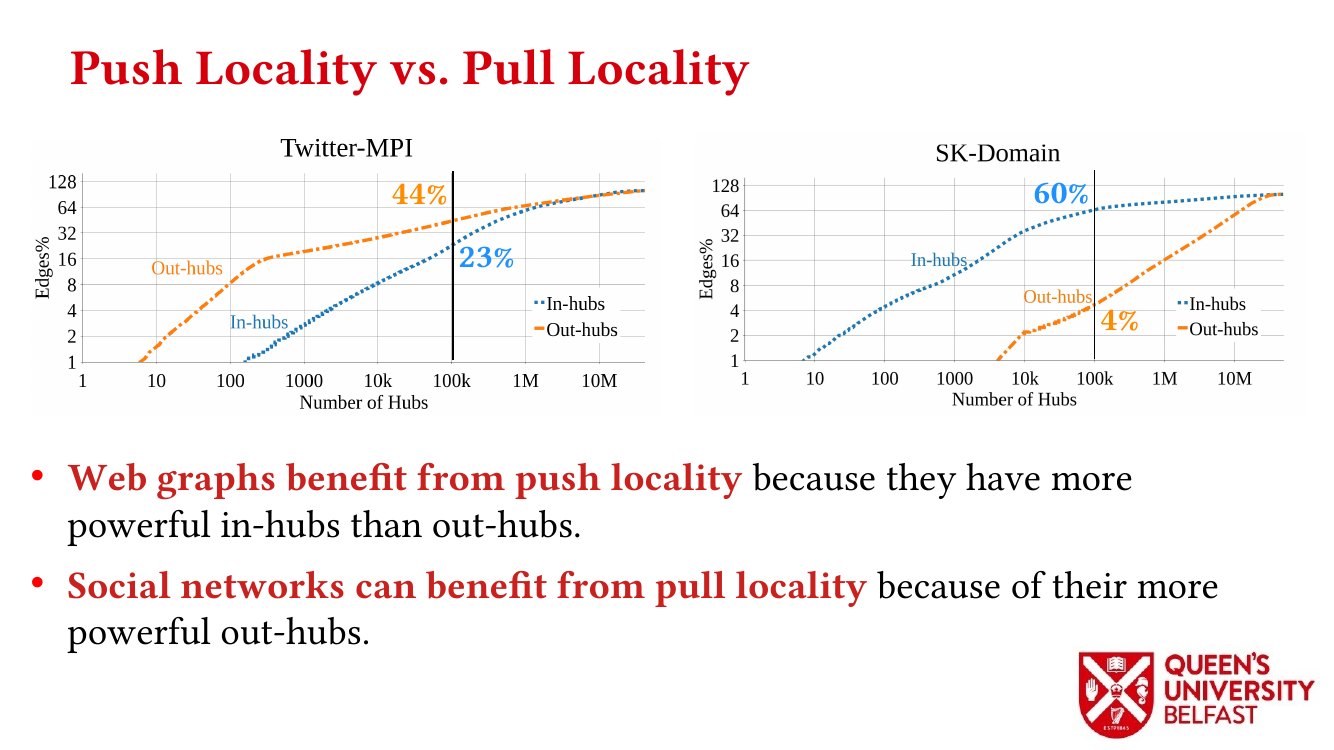
First, we study the structure of real-world graph datasets with skewed degree distribution and the applicability of graph relabeling algorithms as the main restructuring tools to improve performance and memory locality. To that end, we introduce novel locality metrics including Cache Miss Rate Degree Distribution, Effective Cache Size, Push Locality and Pull Locality, and Degree Range Decomposition.
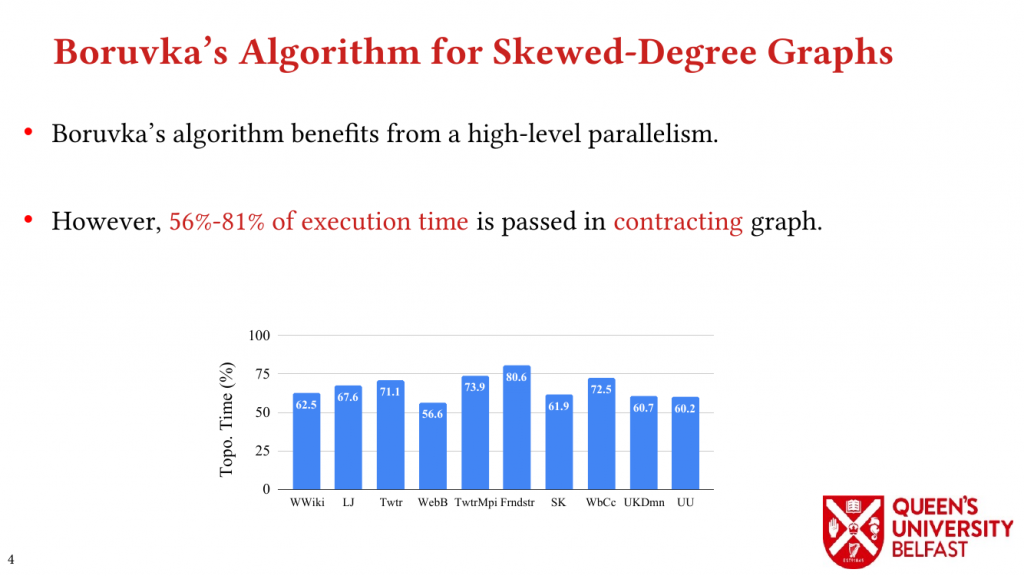
Based on this structural analysis, we introduce the Uniform Memory Demands strategy that (i) recognizes diverse memory demands and behaviours as a source of performance inefficiency, (ii) separates contrasting memory demands into groups with uniform behaviours across each group, and (iii) designs bespoke data structures and algorithms for each group in order to satisfy memory demands with the lowest overhead.
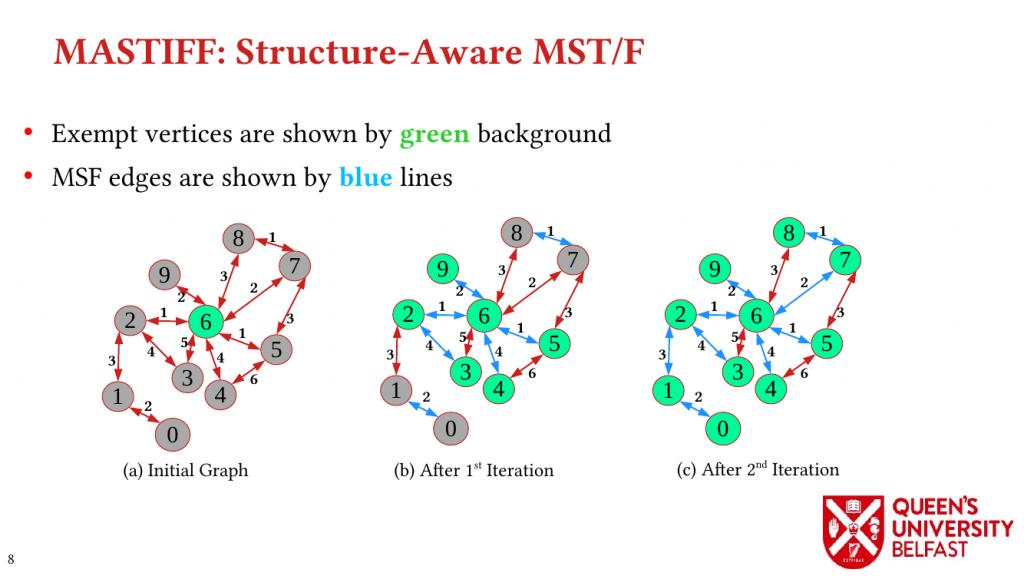
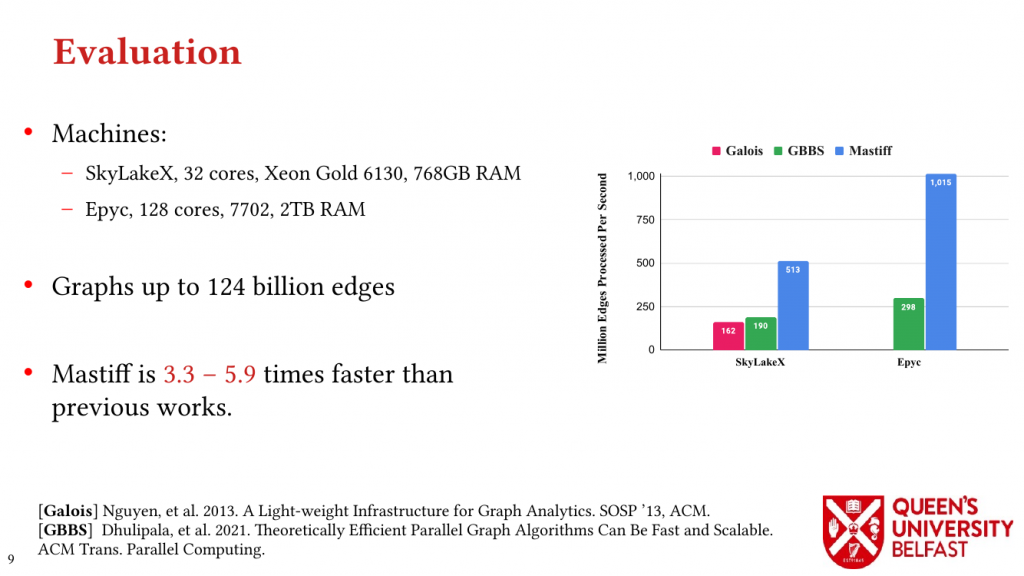
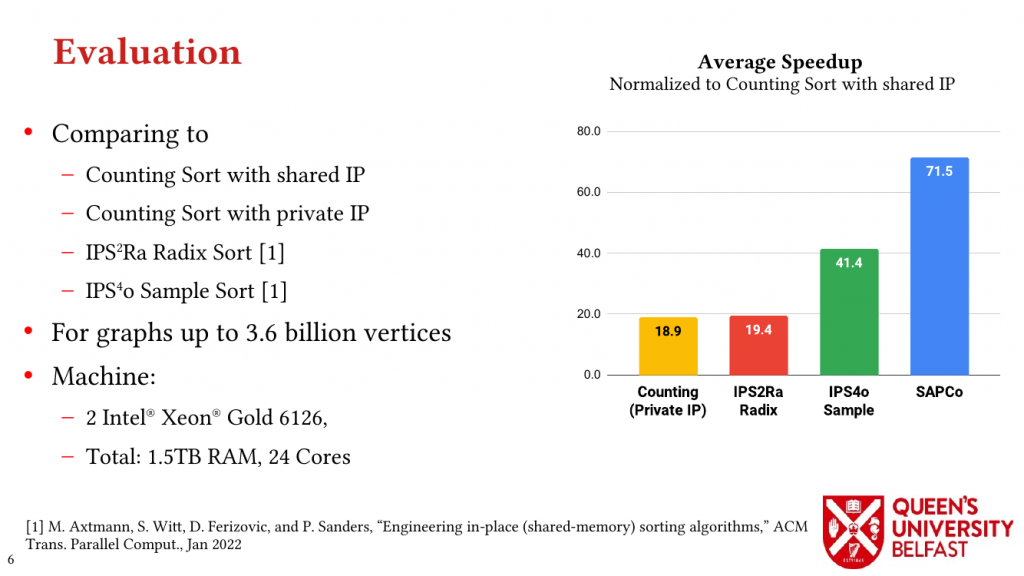
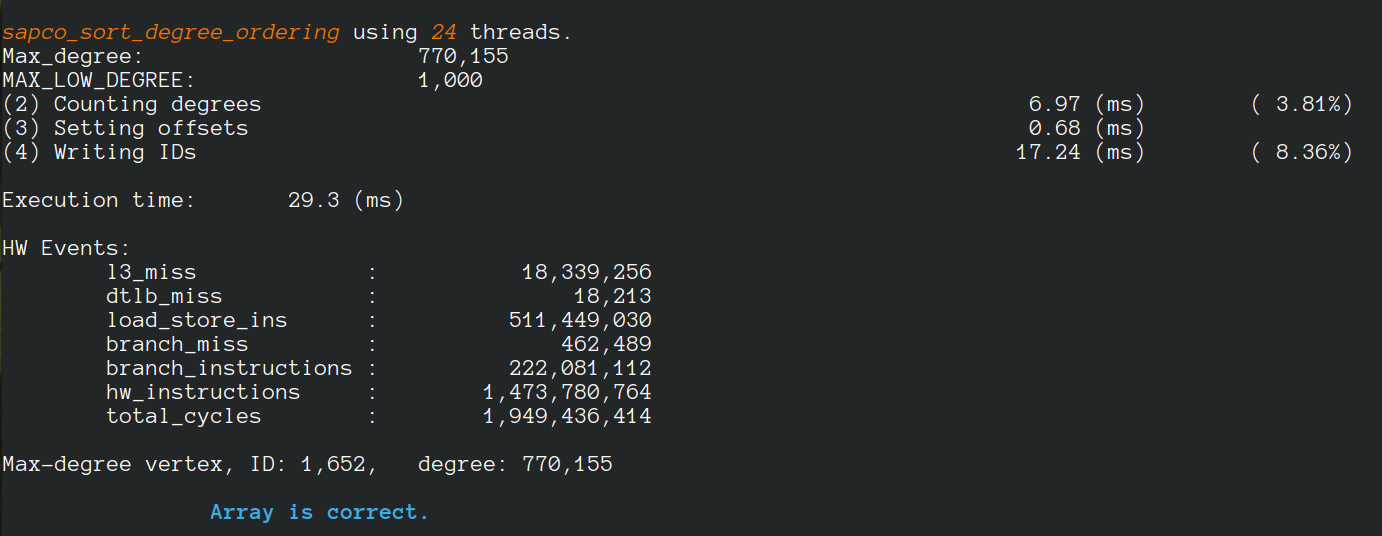
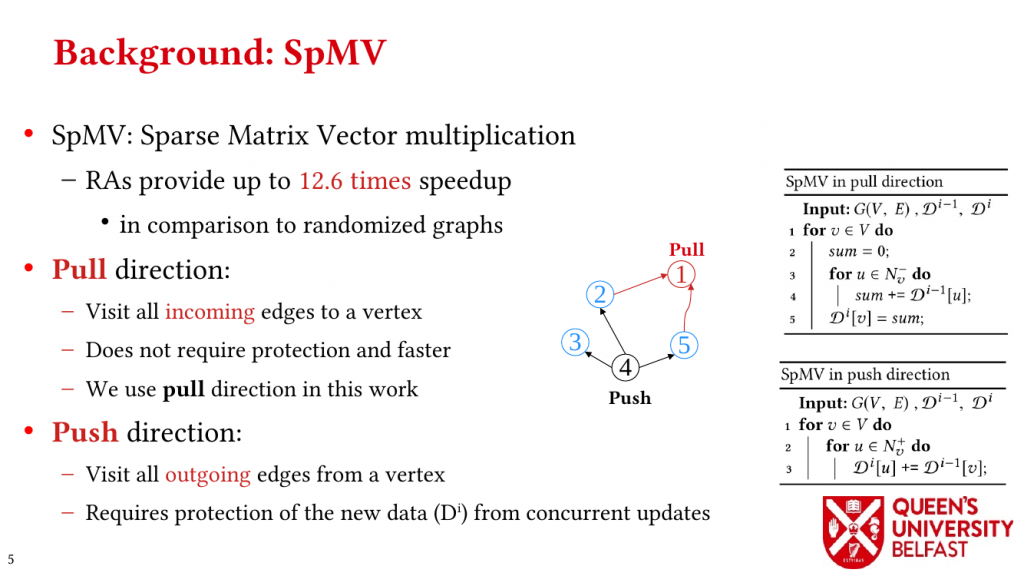
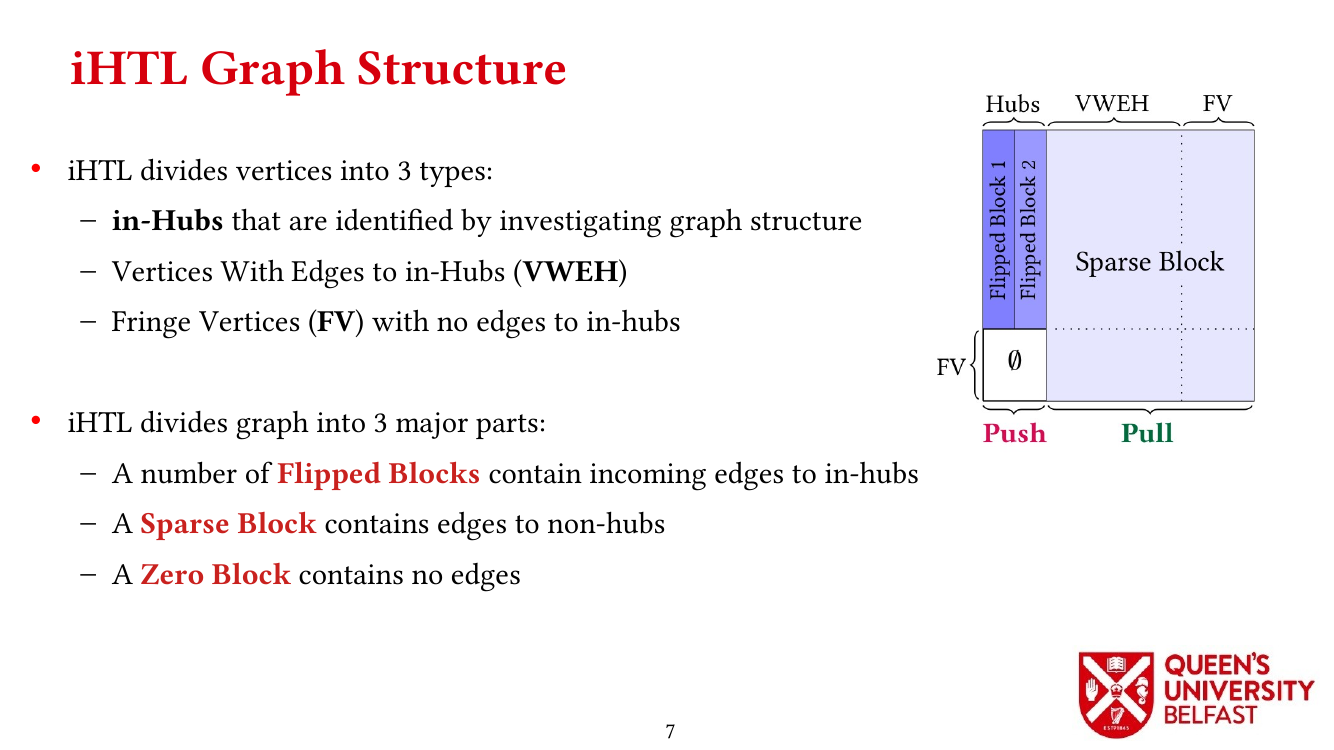
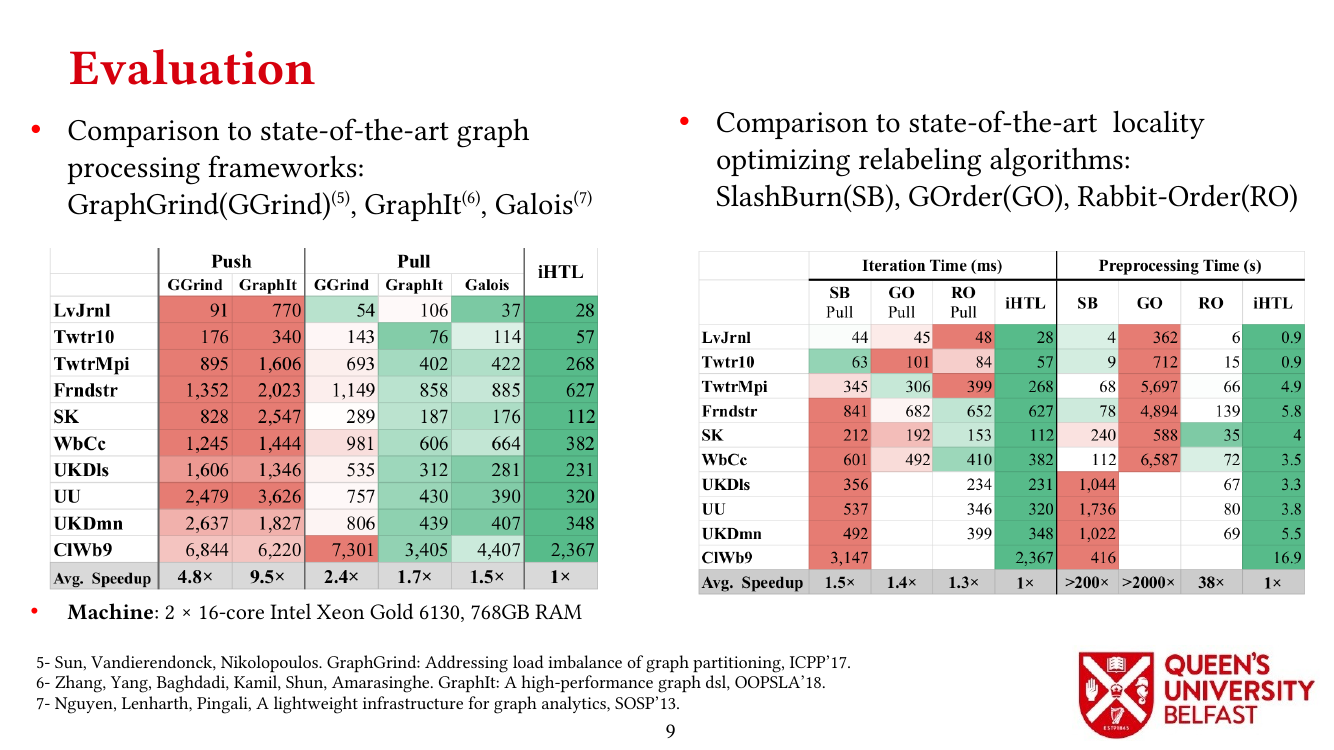
We apply the Uniform Memory Demands strategy to design three graph algorithms with optimized performance: (i) the SAPCo Sort algorithm as a parallel counting sort algorithm that is faster than comparison-based sorting algorithms in degree-ordering of power-law graphs, (ii) the iHTL algorithm that optimizes locality in Sparse Matrix-Vector (SpMV) Multiplication graph algorithms by extracting dense subgraphs containing incoming edges to in-hubs and processing them in the push direction, and (iii) the LOTUS algorithm that optimizes locality in Triangle Counting by separating different caching demands and deploying specific data structure and algorithm for each of them.
Bibtex
@phdthesis{ODSAGA-ethos.874822,
title = {On Designing Structure-Aware High-Performance Graph Algorithms},
author = {Mohsen Koohi Esfahani},
year = 2022,
url = {https://blogs.qub.ac.uk/DIPSA/On-Designing-Structure-Aware-High-Performance-Graph-Algorithms-PhD-Thesis/},
school = {Queen's University Belfast},
EThOSID = {uk.bl.ethos.874822}
}Related Posts
- On Optimizing Locality of Graph Transposition on Modern Architectures

- Random Vertex Relabelling in LaganLighter

- Minimum Spanning Forest of MS-BioGraphs

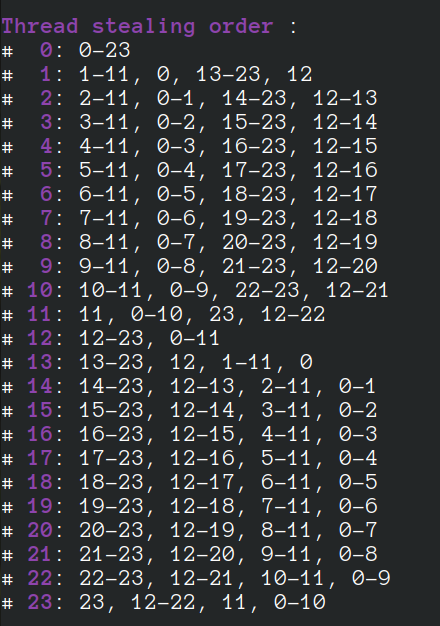
- Topology-Based Thread Affinity Setting (Thread Pinning) in OpenMP

- ParaGrapher Integrated to LaganLighter

- On Designing Structure-Aware High-Performance Graph Algorithms (PhD Thesis)

- LaganLighter Source Code

- MASTIFF: Structure-Aware Minimum Spanning Tree/Forest – ICS’22

- SAPCo Sort: Optimizing Degree-Ordering for Power-Law Graphs – ISPASS’22 (Poster)

- LOTUS: Locality Optimizing Triangle Counting – PPOPP’22

- Locality Analysis of Graph Reordering Algorithms – IISWC’21

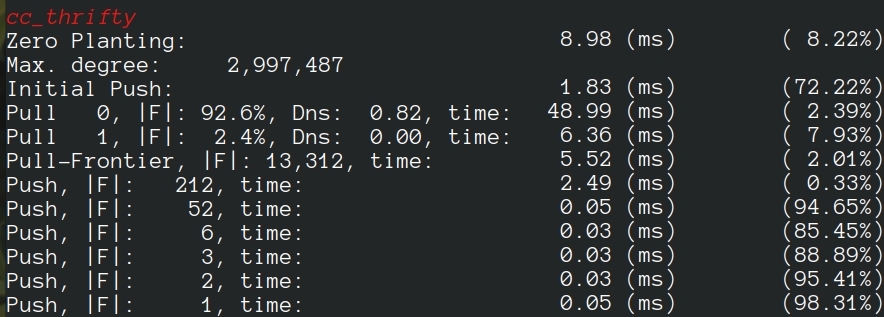
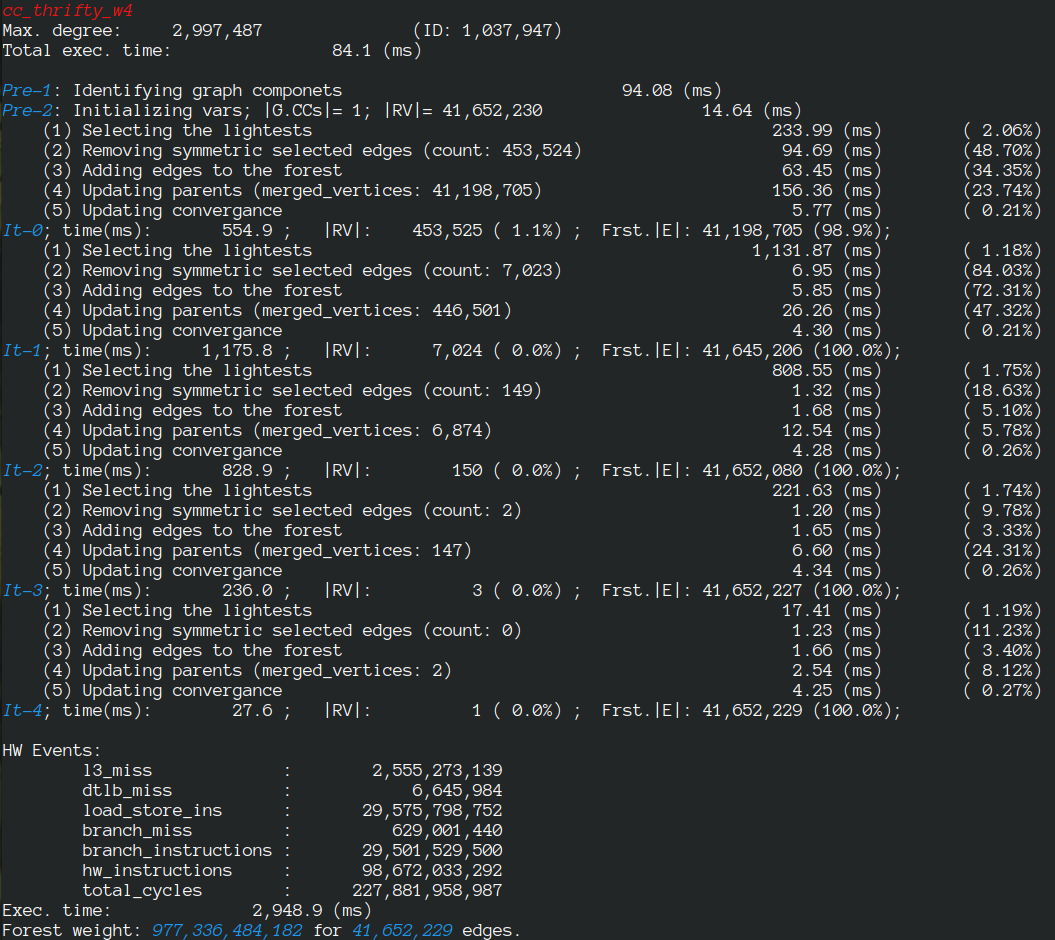
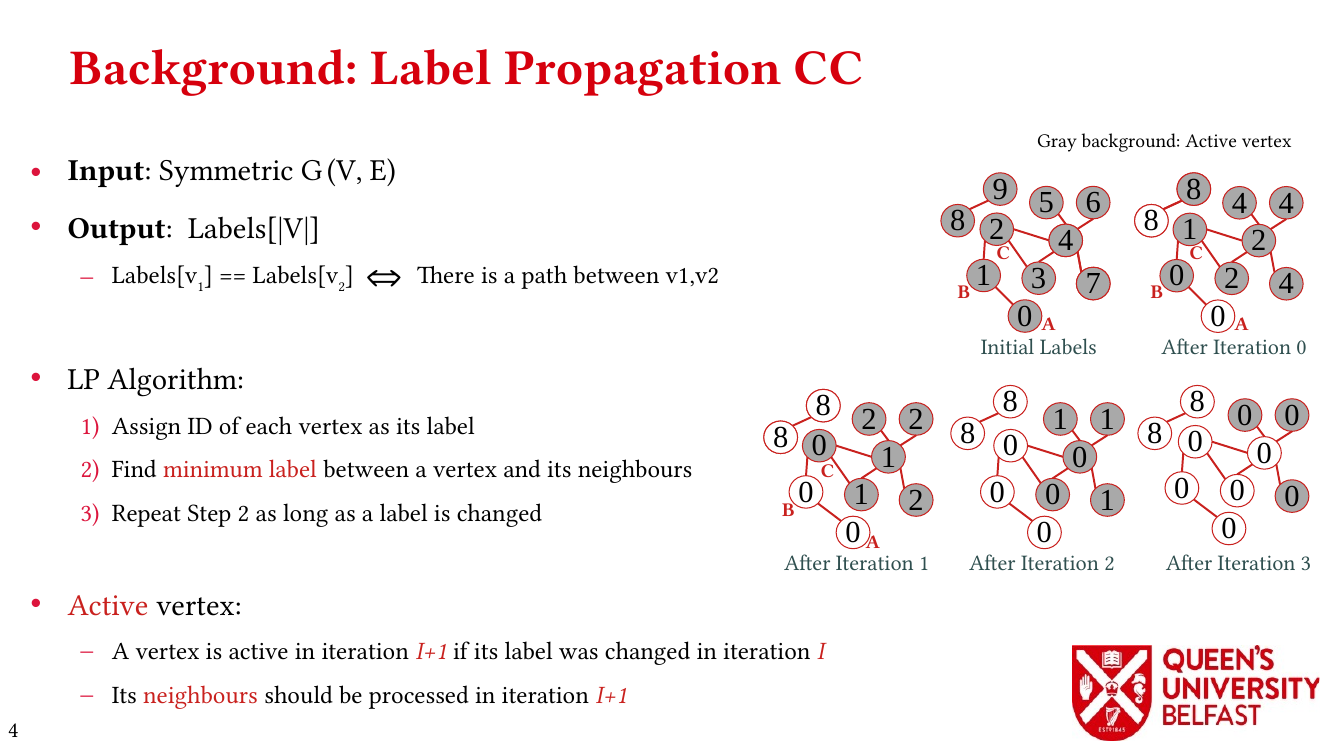
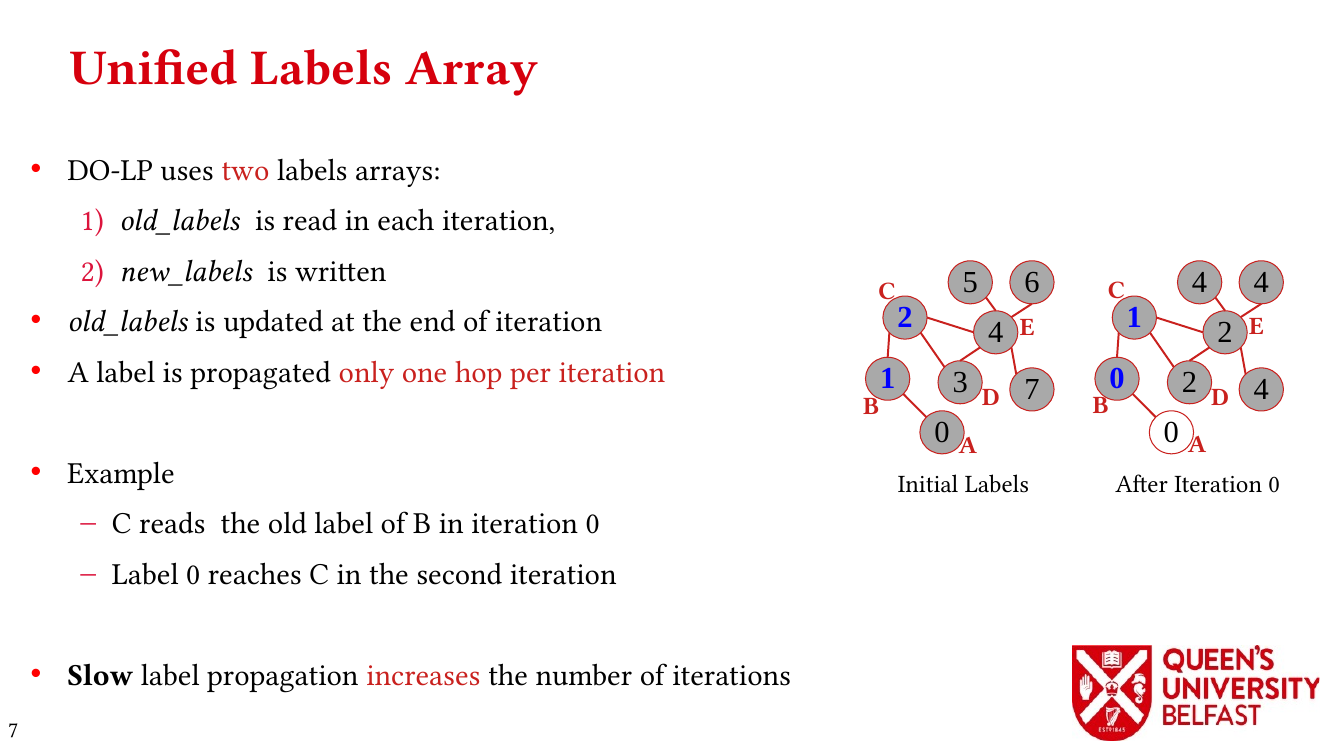
- Thrifty Label Propagation: Fast Connected Components for Skewed-Degree Graphs – IEEE CLUSTER’21

- Exploiting in-Hub Temporal Locality in SpMV-based Graph Processing – ICPP’21

- How Do Graph Relabeling Algorithms Improve Memory Locality? ISPASS’21 (Poster)