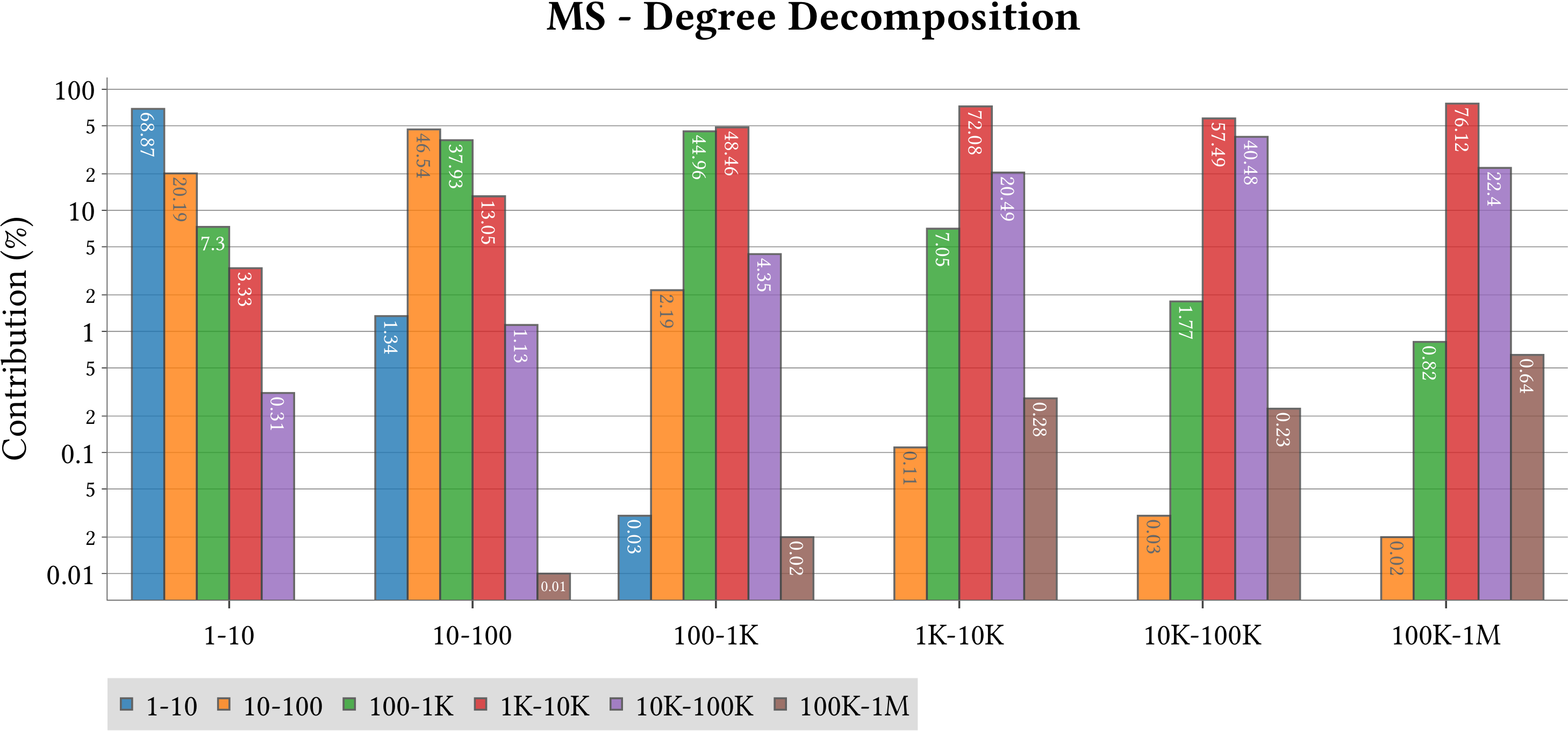
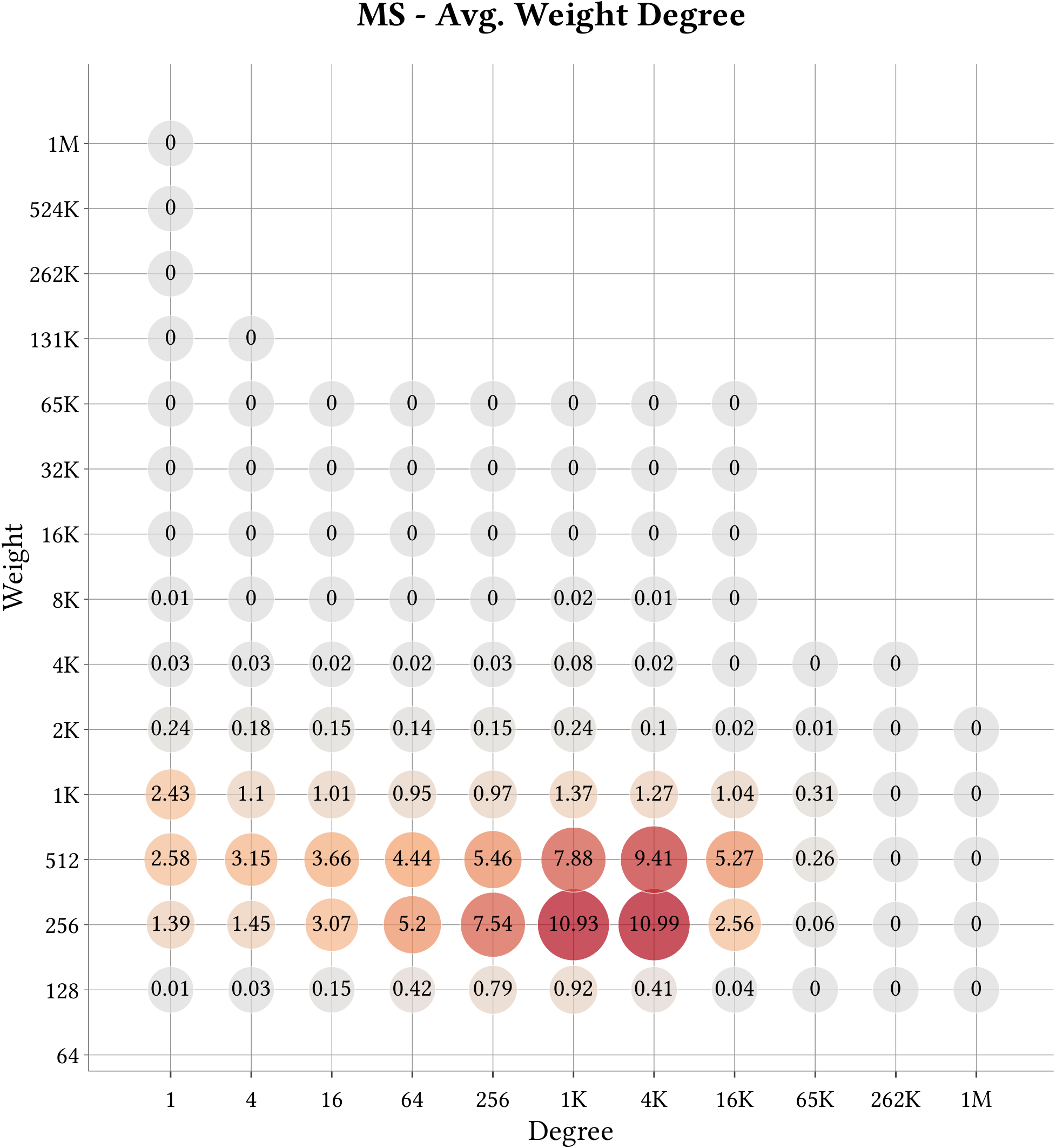
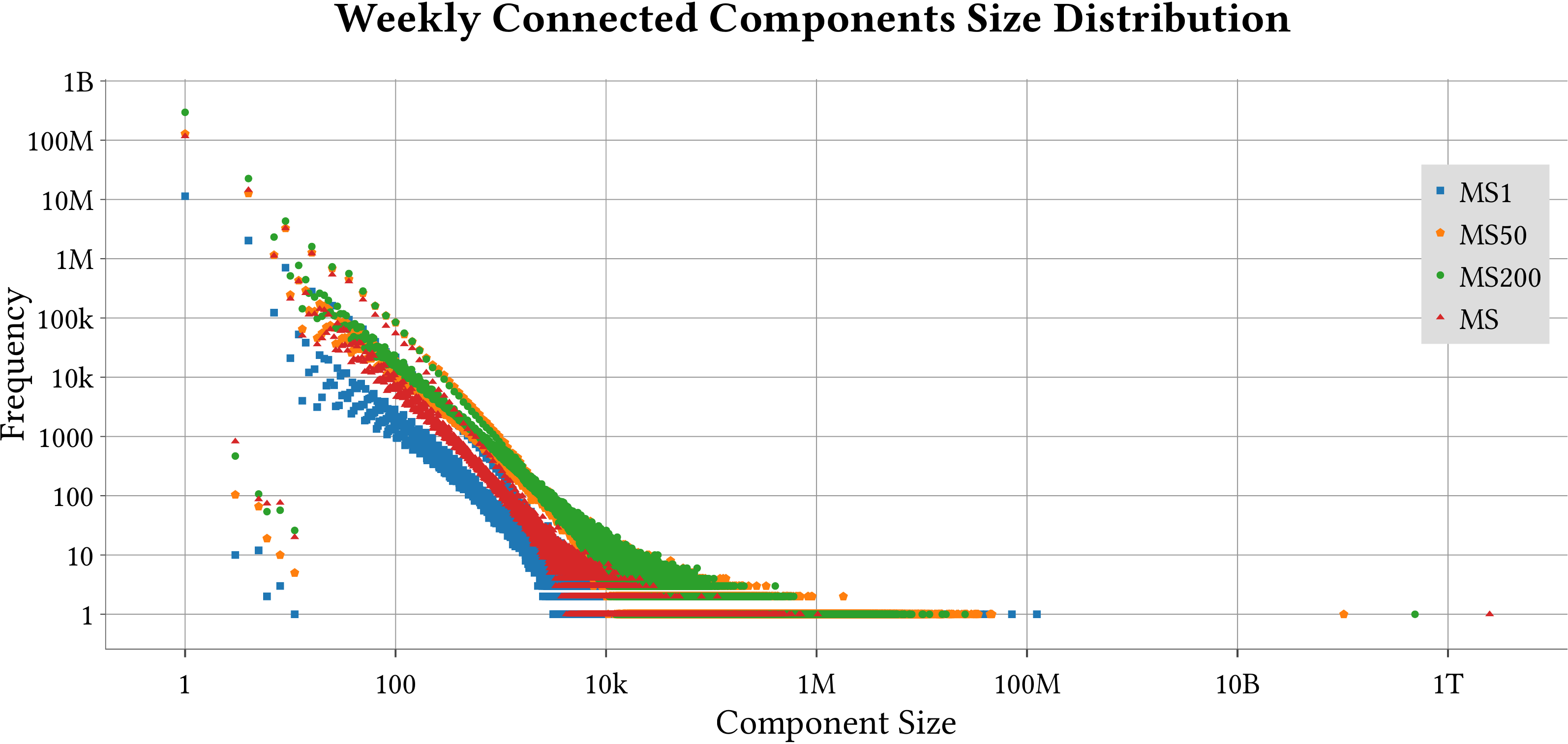
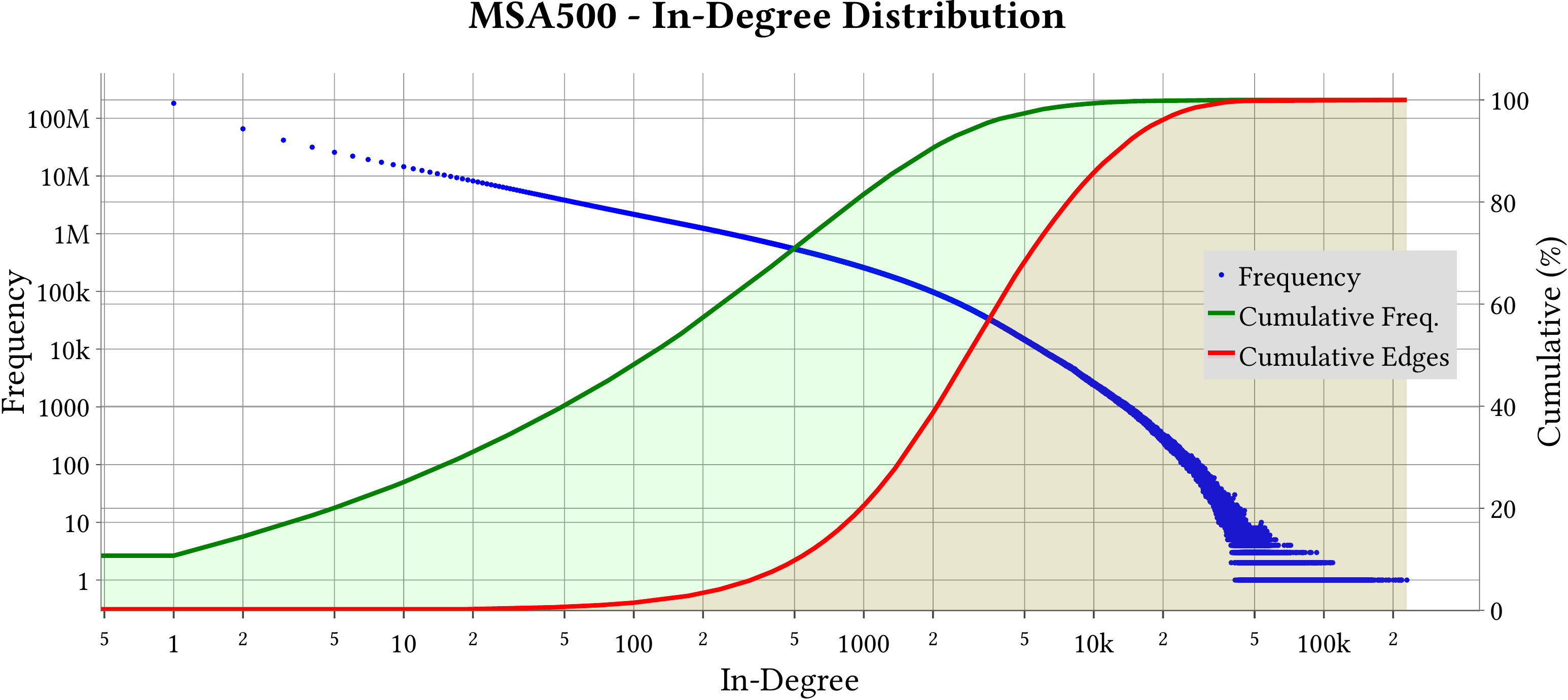
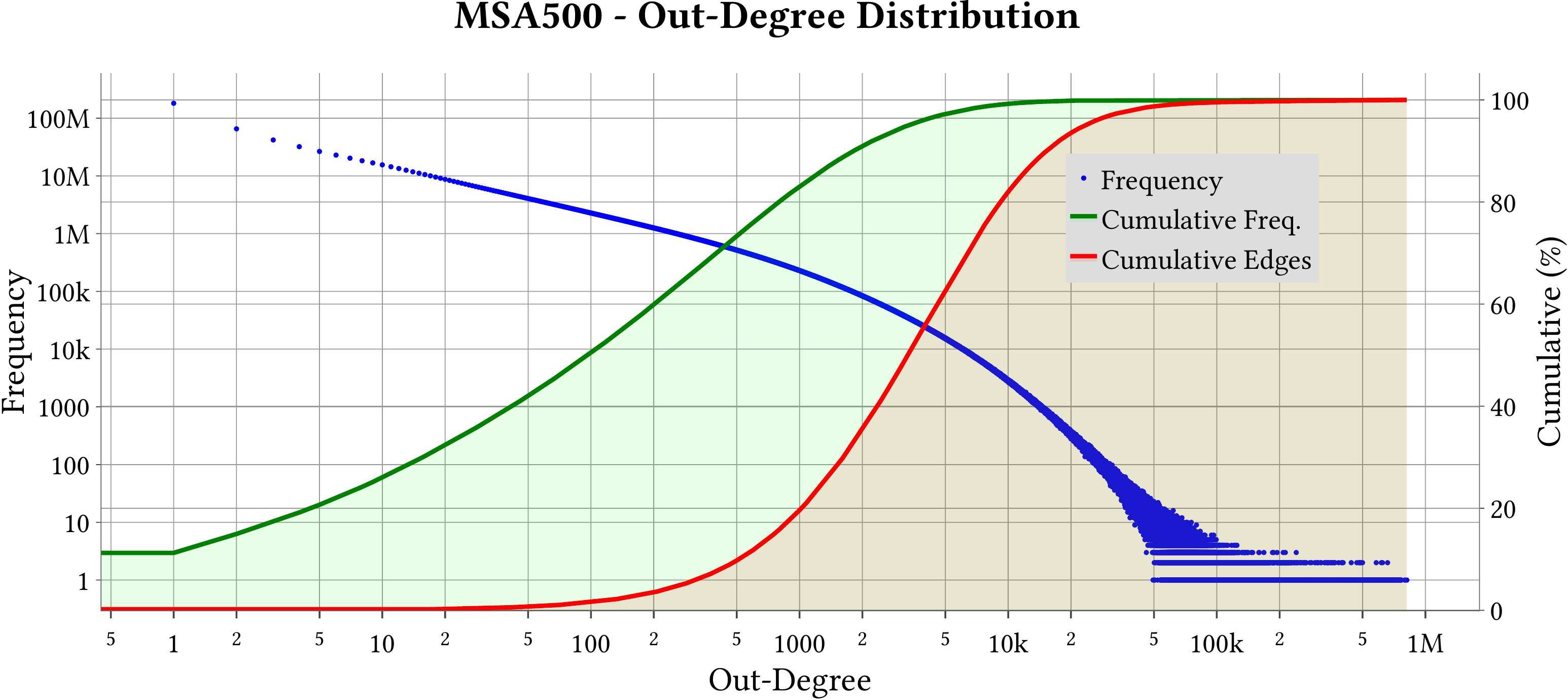
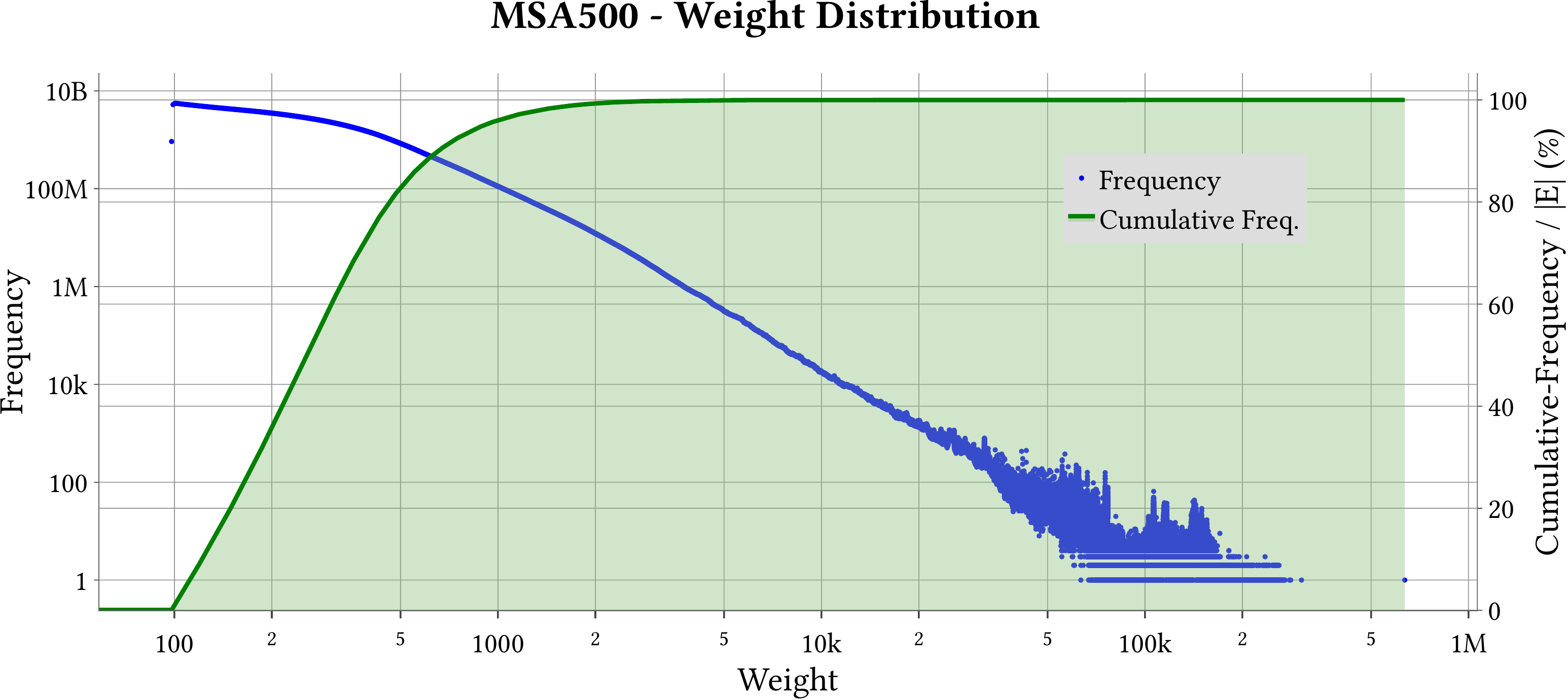
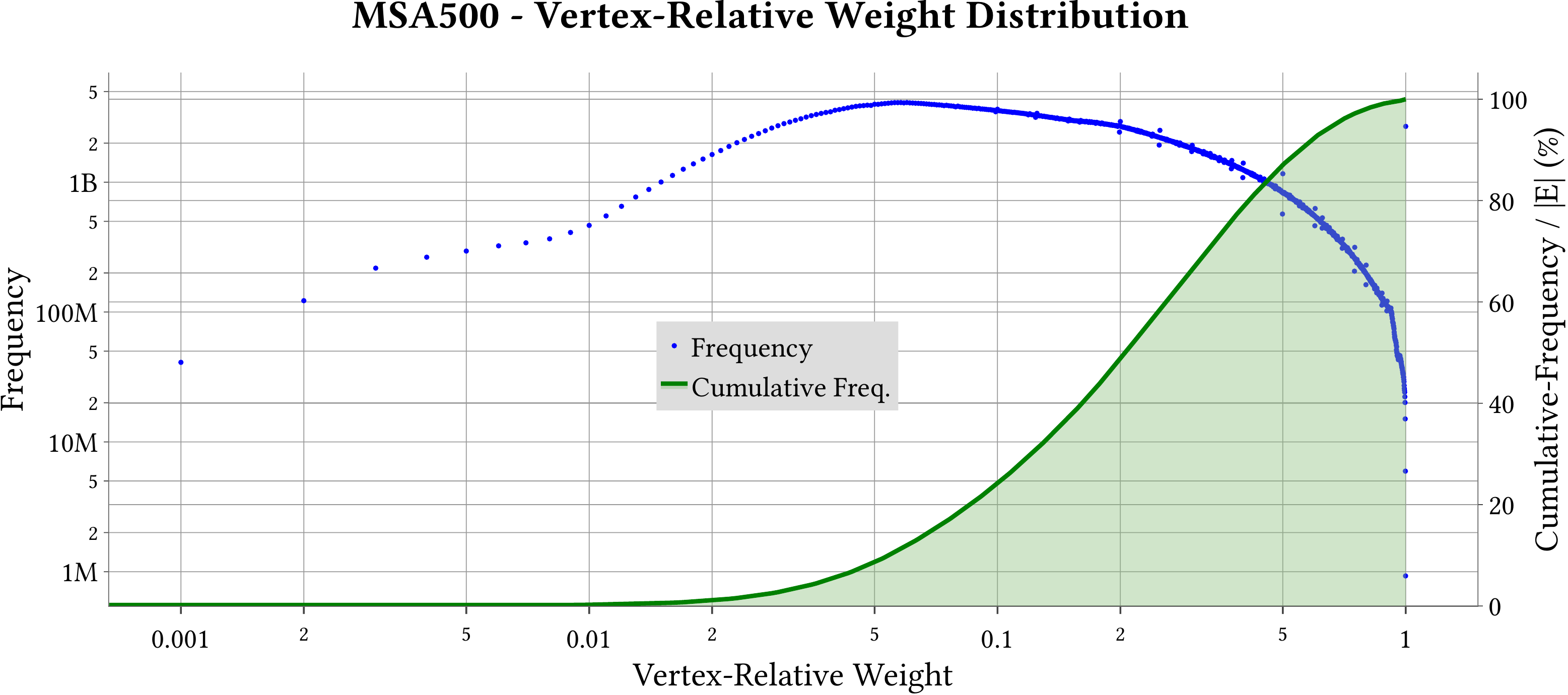
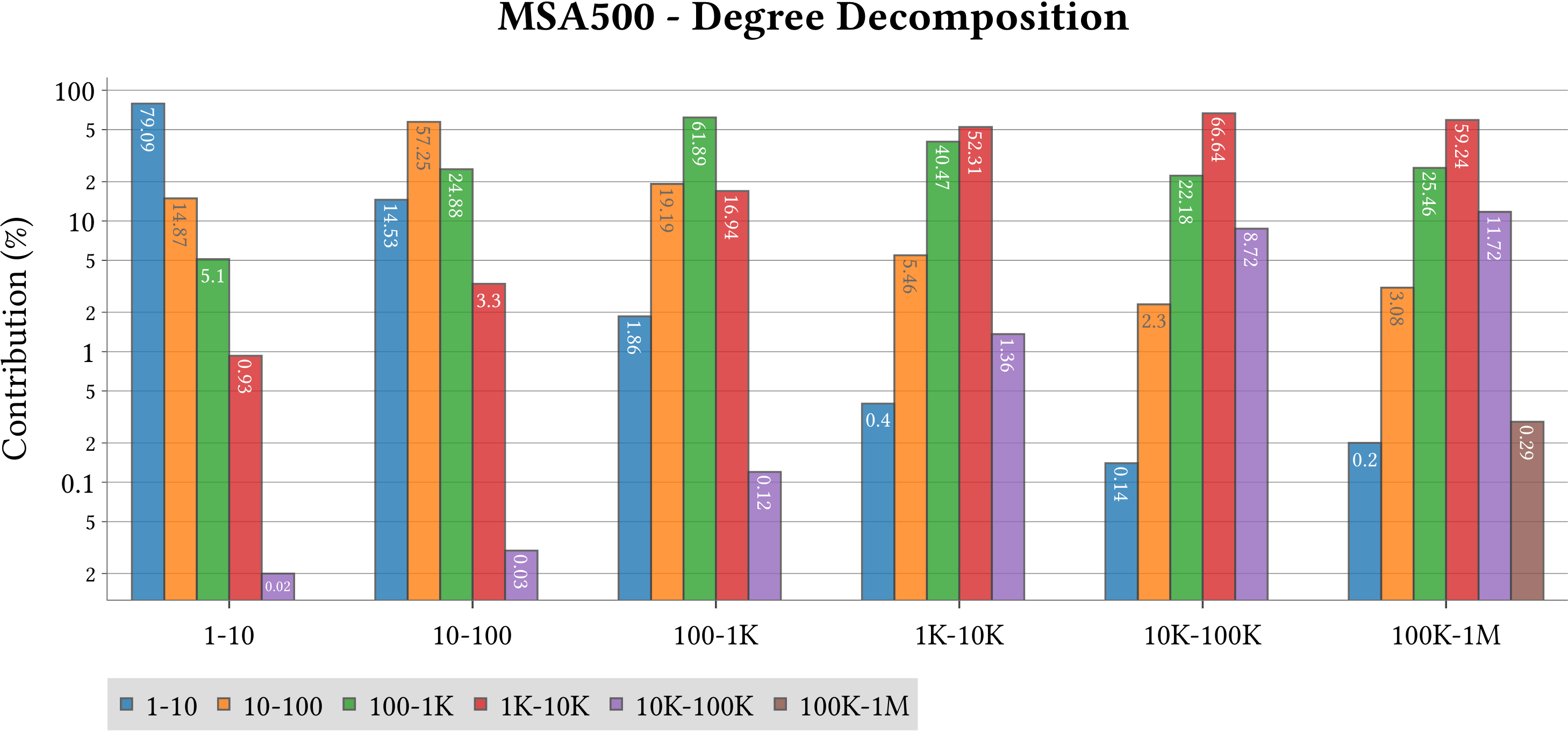
We use MASTIFF to compute the weight of Minimum Spanning Forest (MST) of MS-BioGraphs while ignoring self-edges of the graphs.
– MS1
Using machine with 24 cores.
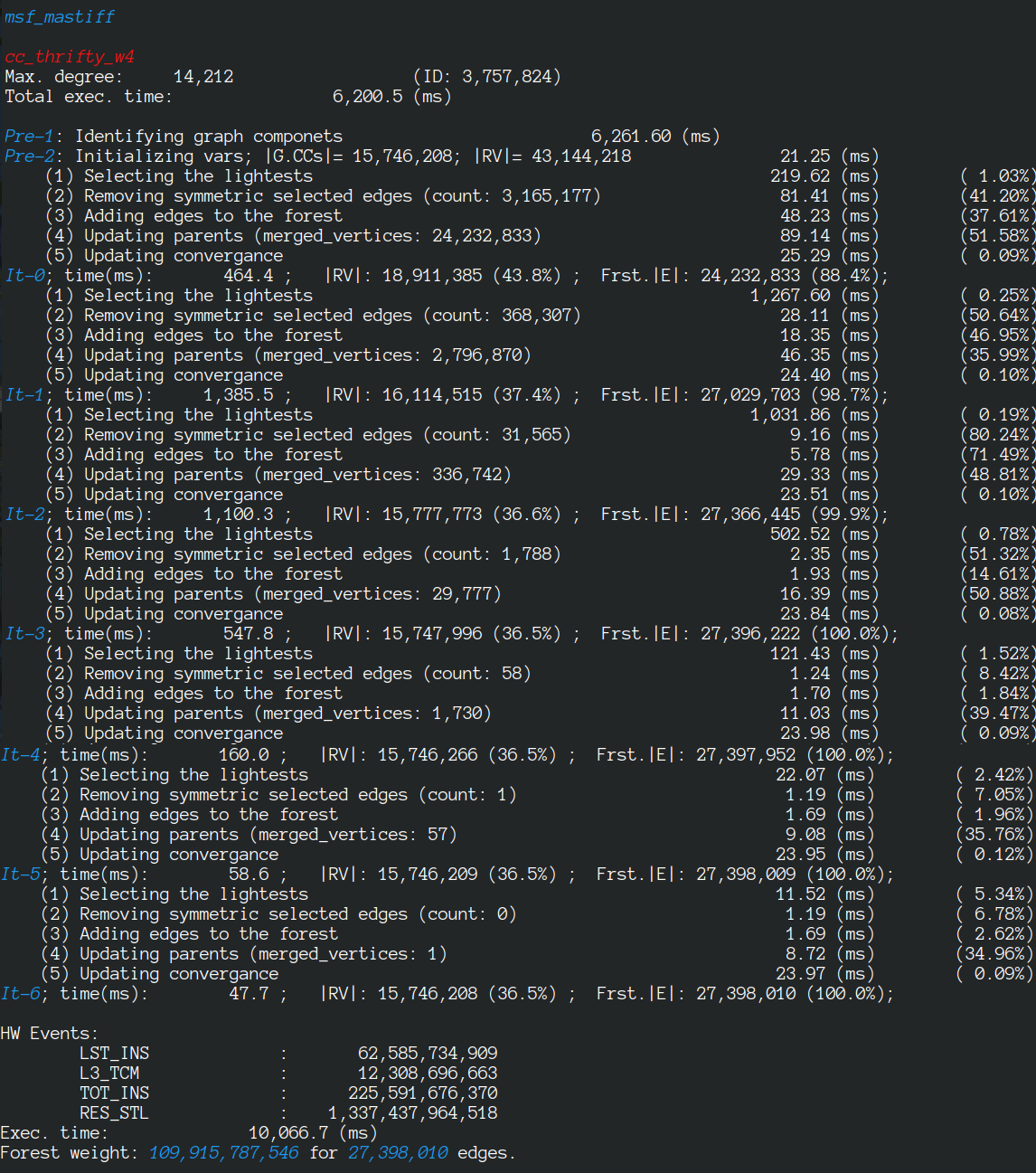
MSF weight: 109,915,787,546
– MS50
Using machine with 128 cores.
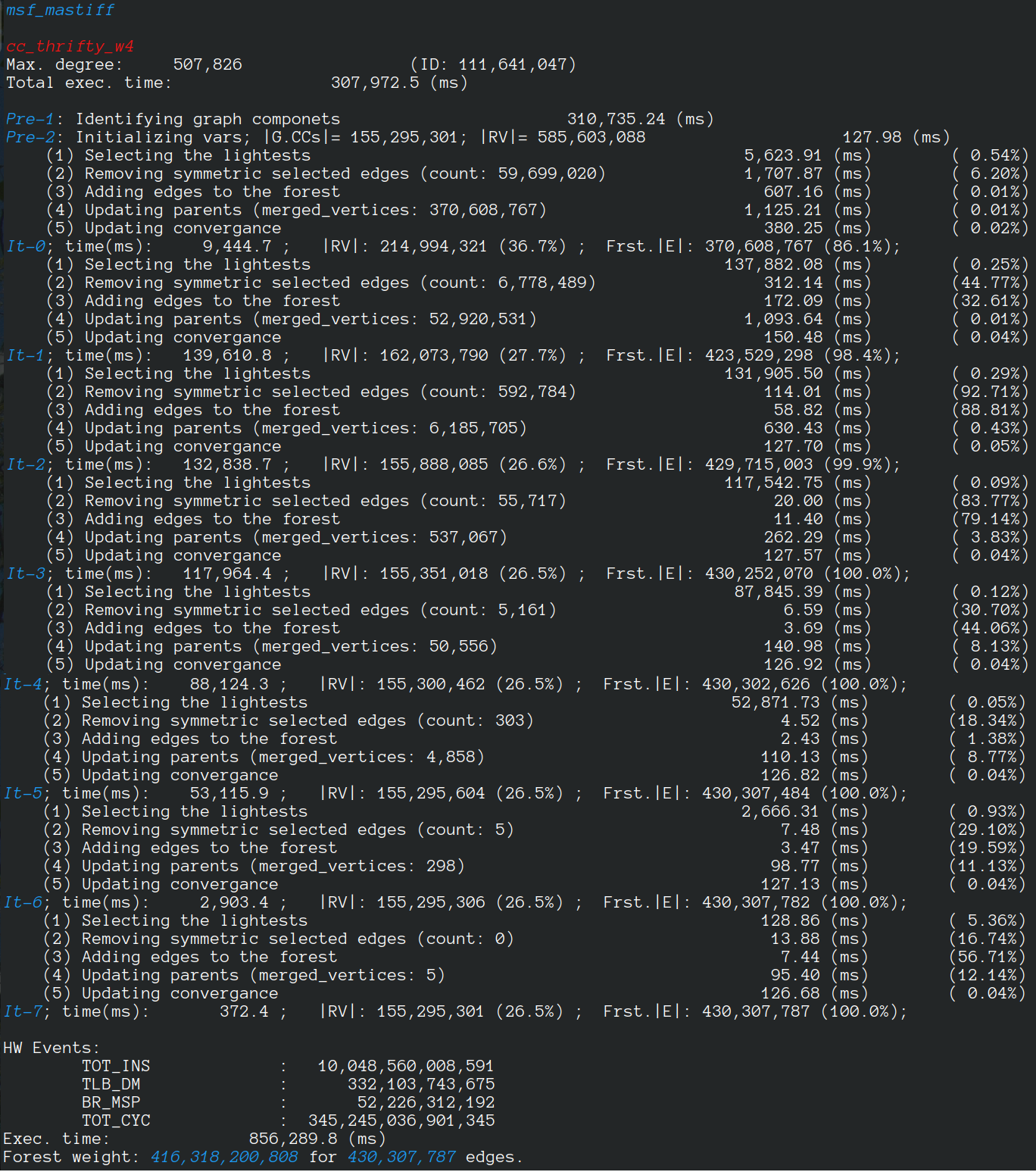
MSF weight: 416,318,200,808
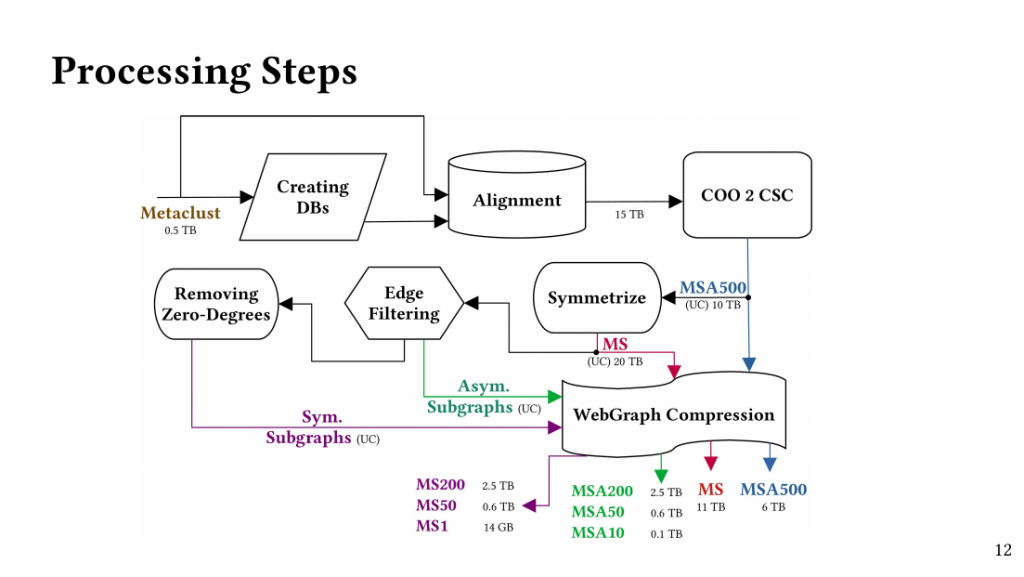
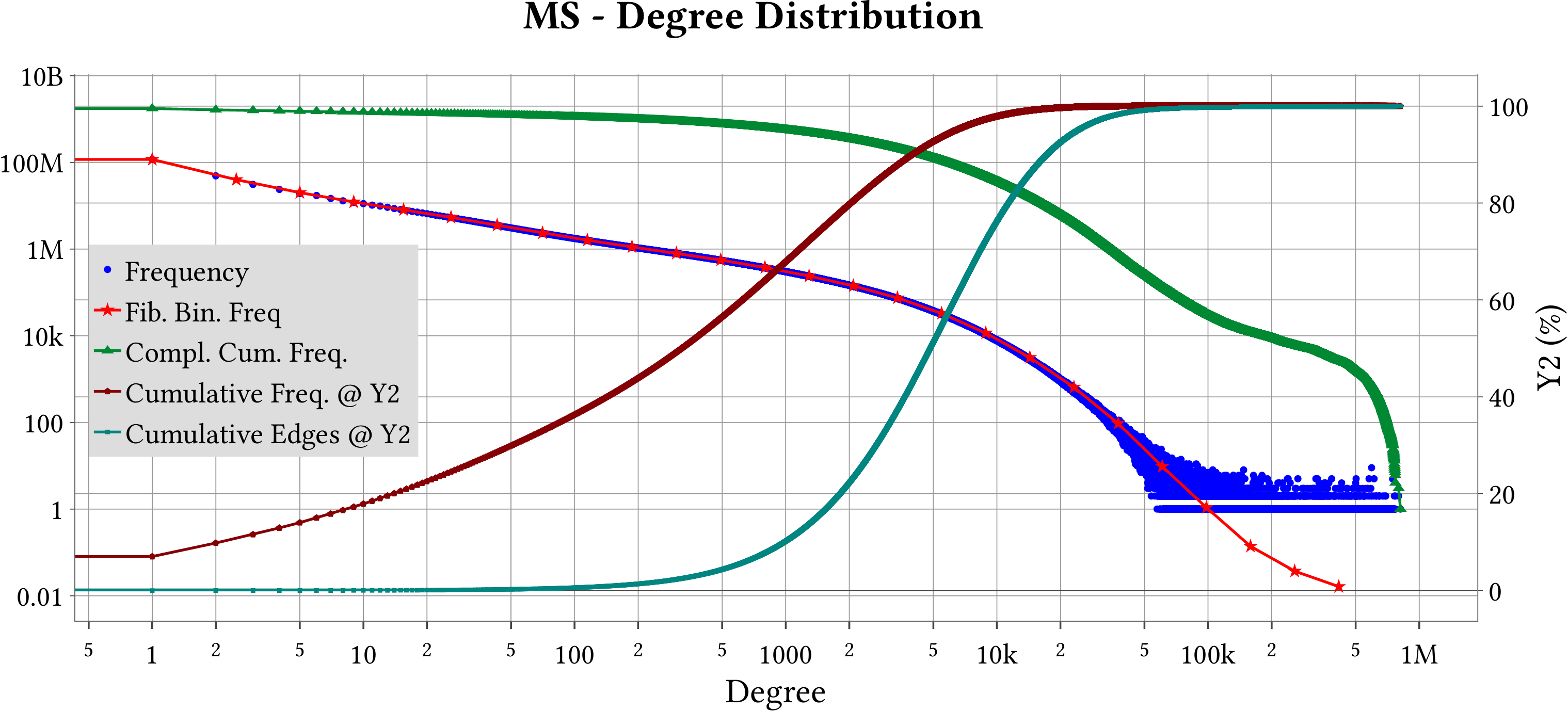
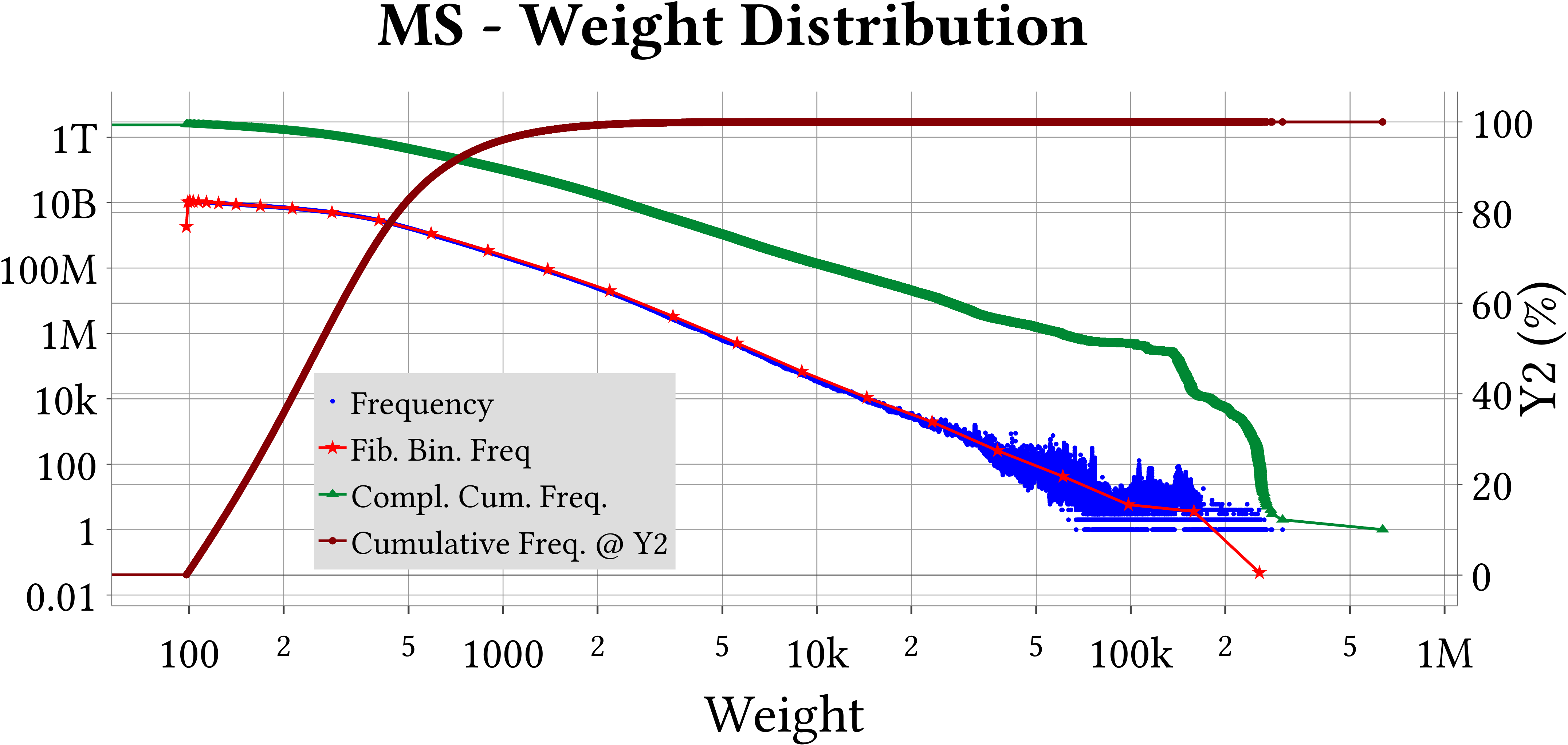
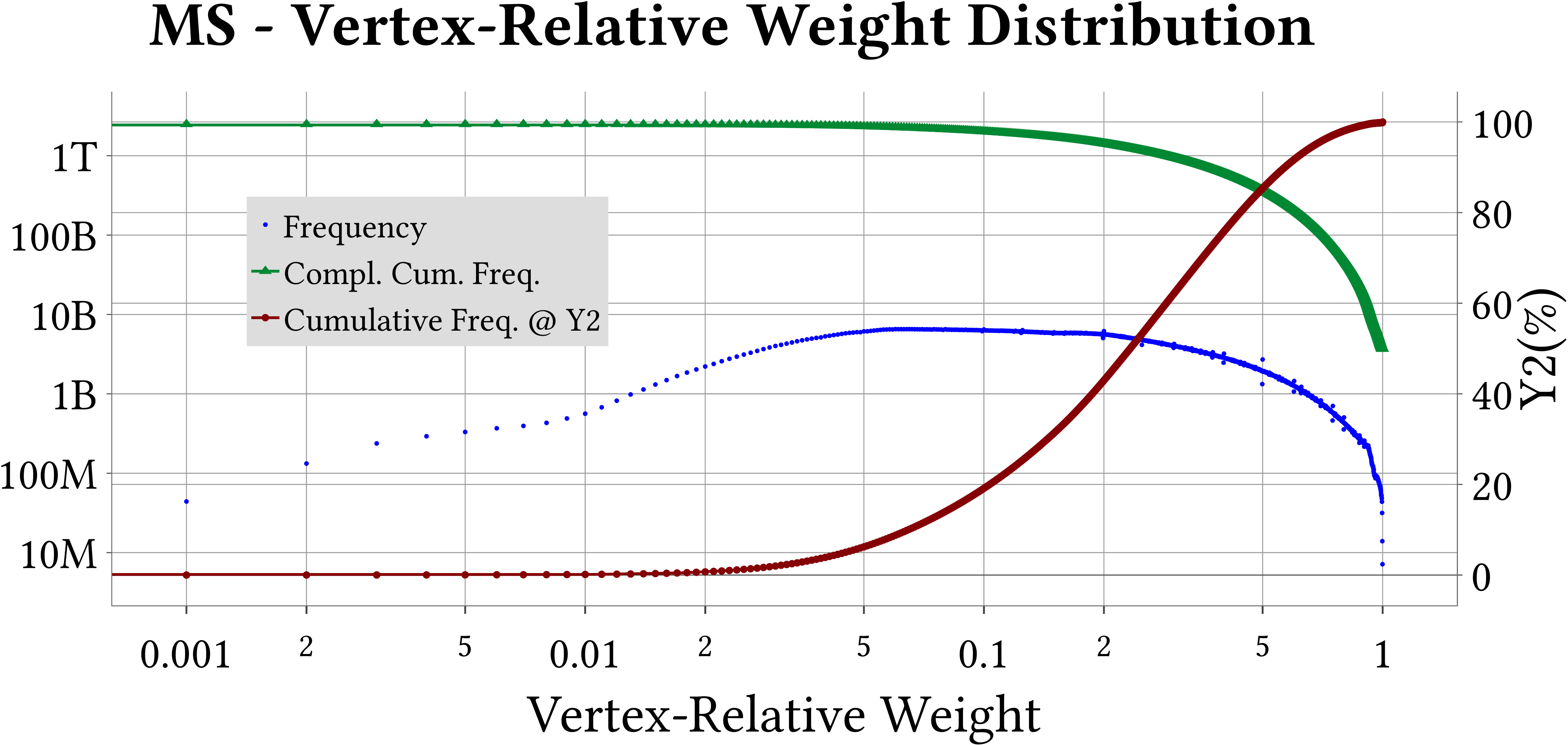
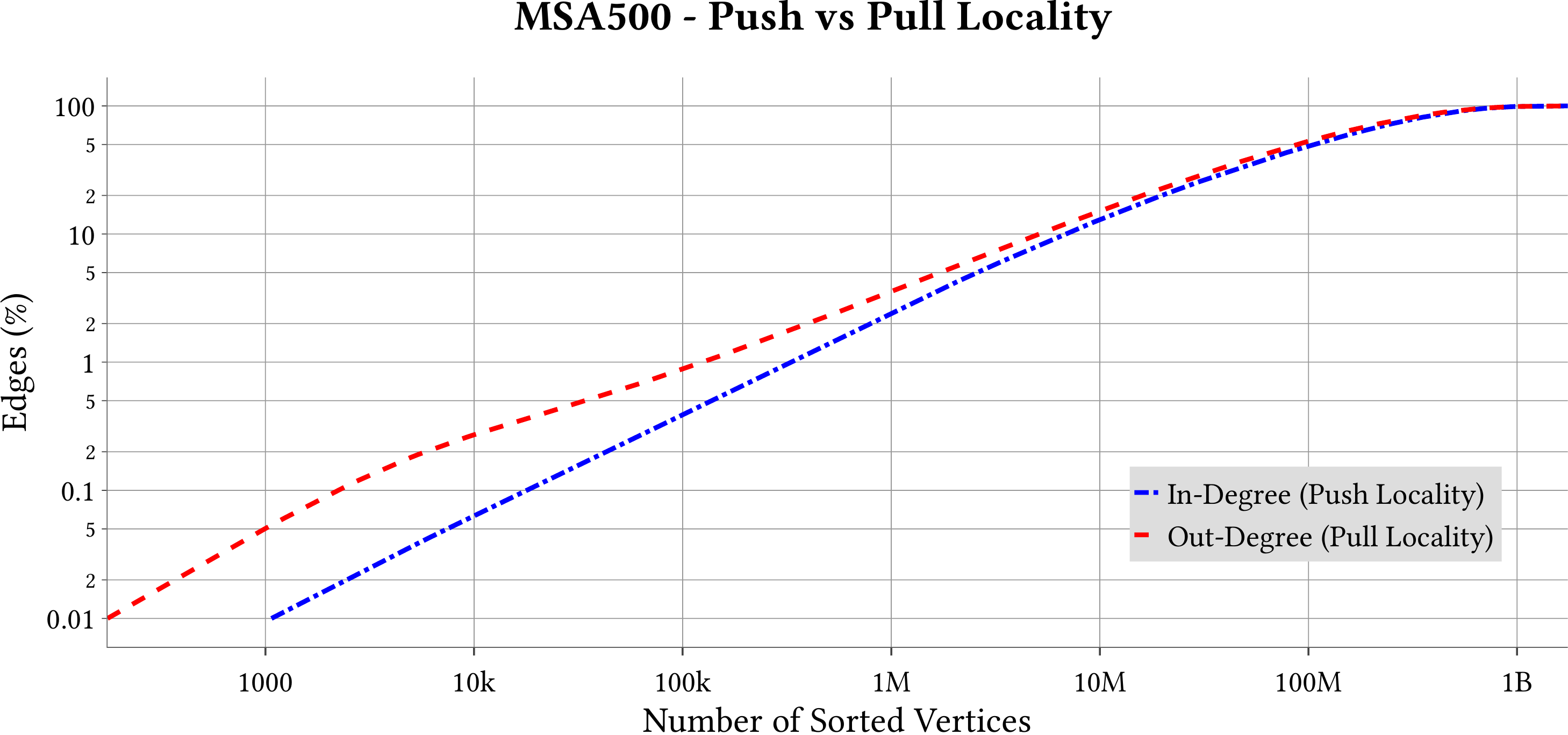
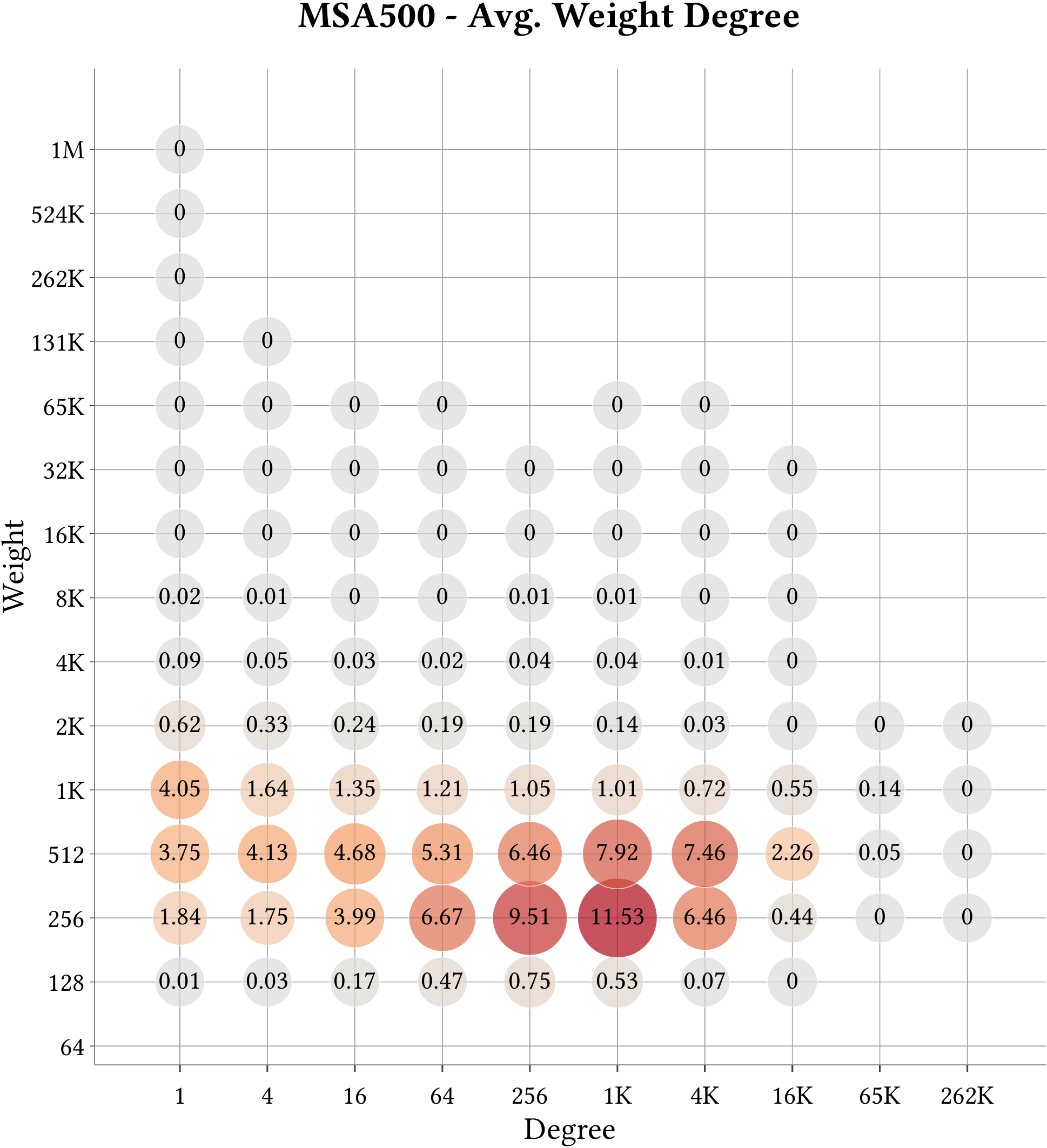
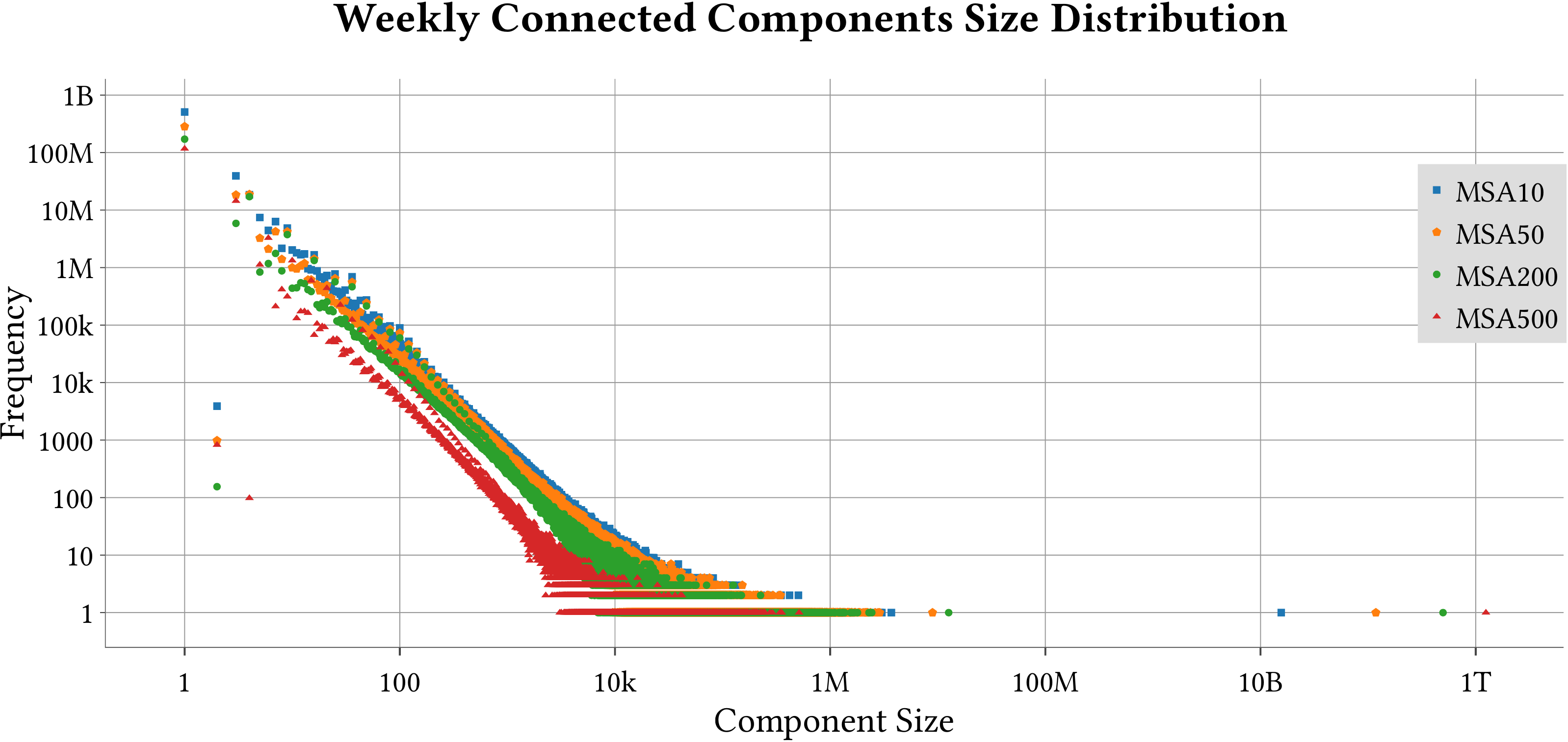
MS-BioGraphs
Related Posts
- Minimum Spanning Forest of MS-BioGraphs

- MS-BioGraphs on IEEE DataPort

- ParaGrapher Source Code For WebGraph Types

- On Overcoming HPC Challenges of Trillion-Scale Real-World Graph Datasets – BigData’23 (Short Paper)

- Dataset Announcement: MS-BioGraphs, Trillion-Scale Public Real-World Sequence Similarity Graphs – IISWC’23 (Poster)

- MS-BioGraphs: Sequence Similarity Graph Datasets

- MS-BioGraphs MS

- MS-BioGraphs MSA500

- MS-BioGraphs MS200

- MS-BioGraphs MSA200

- MS-BioGraphs MS50

- MS-BioGraphs MSA50

- MS-BioGraphs MSA10

- MS-BioGraphs MS1

- MS-BioGraphs Validation

- Random Vertex Relabelling in LaganLighter

- Minimum Spanning Forest of MS-BioGraphs
- Topology-Based Thread Affinity Setting (Thread Pinning) in OpenMP

- An (Incomplete) List of Publicly Available Graph Datasets/Generators

- An Evaluation of Bandwidth of Different Storage Types (HDD vs. SSD vs. LustreFS) for Different Block Sizes and Different Parallel Read Methods (mmap vs pread vs read)

- SIMD Bit Twiddling Hacks

- LaganLighter Source Code

- On Optimizing Locality of Graph Transposition on Modern Architectures

- Random Vertex Relabelling in LaganLighter
- Minimum Spanning Forest of MS-BioGraphs
- Topology-Based Thread Affinity Setting (Thread Pinning) in OpenMP
- ParaGrapher Integrated to LaganLighter

- On Designing Structure-Aware High-Performance Graph Algorithms (PhD Thesis)

- LaganLighter Source Code
- MASTIFF: Structure-Aware Minimum Spanning Tree/Forest – ICS’22

- SAPCo Sort: Optimizing Degree-Ordering for Power-Law Graphs – ISPASS’22 (Poster)

- LOTUS: Locality Optimizing Triangle Counting – PPOPP’22

- Locality Analysis of Graph Reordering Algorithms – IISWC’21

- Thrifty Label Propagation: Fast Connected Components for Skewed-Degree Graphs – IEEE CLUSTER’21

- Exploiting in-Hub Temporal Locality in SpMV-based Graph Processing – ICPP’21

- How Do Graph Relabeling Algorithms Improve Memory Locality? ISPASS’21 (Poster)