To evaluate the impacts of locality-optimizing reordering algorithms, a baseline is required. To create the baseline a random assignment of IDs to vertices may be used to produce a representation of the graph with reduced locality [ DOI:10.1109/ISPASS57527.2023.00029, DOI:10.1109/IISWC53511.2021.00020 ].
To that end, we create the random_ordering() function in relabel.c file. It consists a number of iterations. In each iteration, concurrent threads traverse the list of vertices and assign them new IDs. The function uses xoshiro to produce random numbers.
The alg4_randomize tests this function for a number of graphs. For each dataset, an initial plot of degree distribution of Neighbor to Neighbor Average ID Distance (N2N AID) [DOI:10.1109/IISWC53511.2021.00020] is created. Also, after each iteration of random_ordering() the N2N AID distribution is plotted. This shows the impacts of randomization.
The complete results for all graphs can be seen in this PDF file. The results for some graphs are in the following.
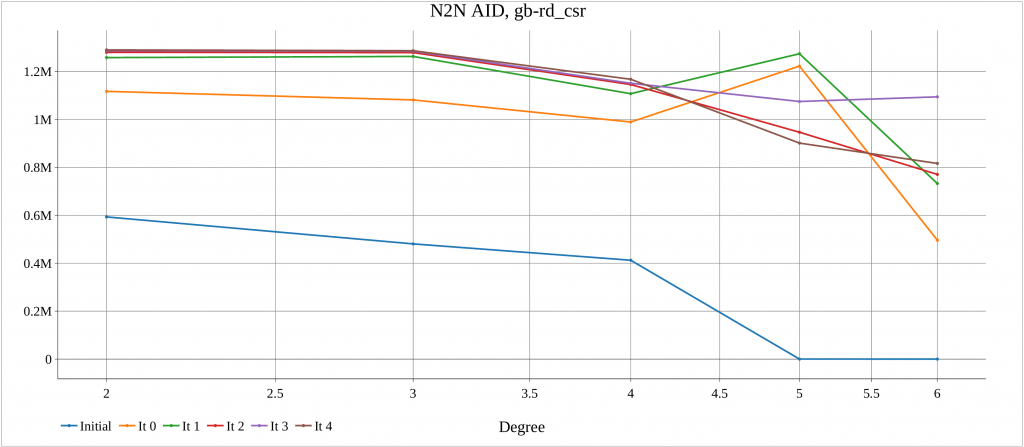
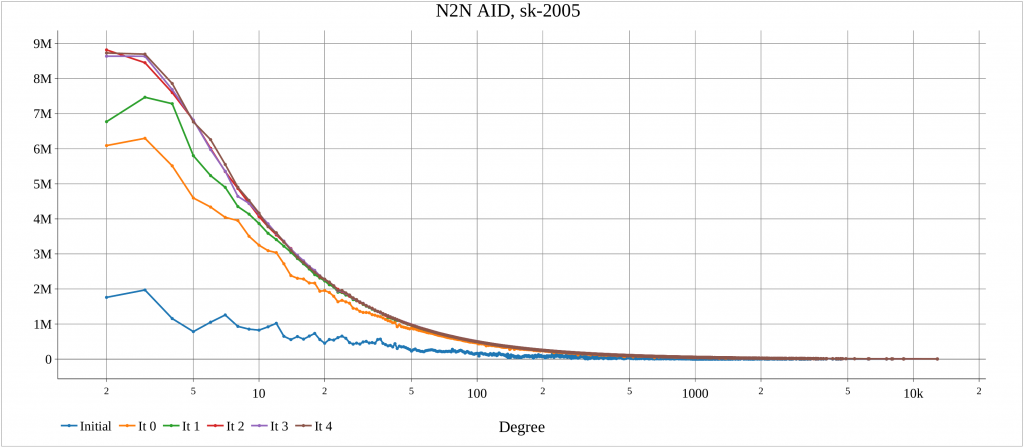
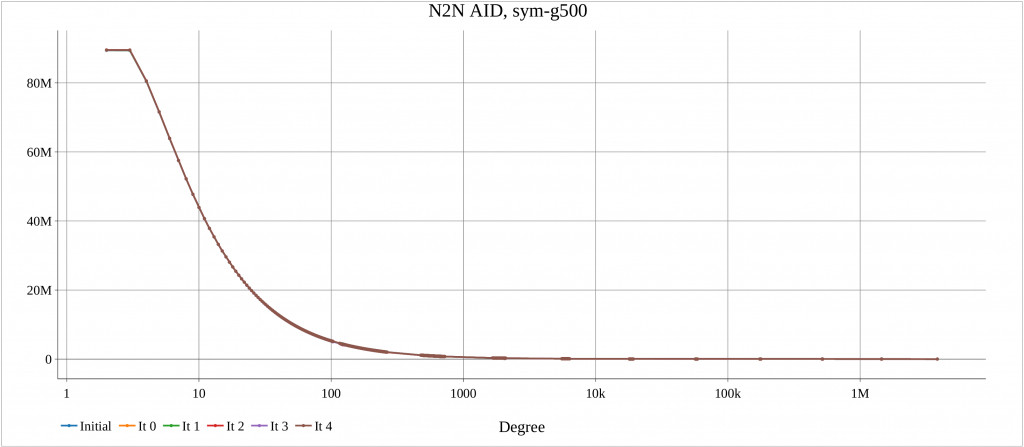
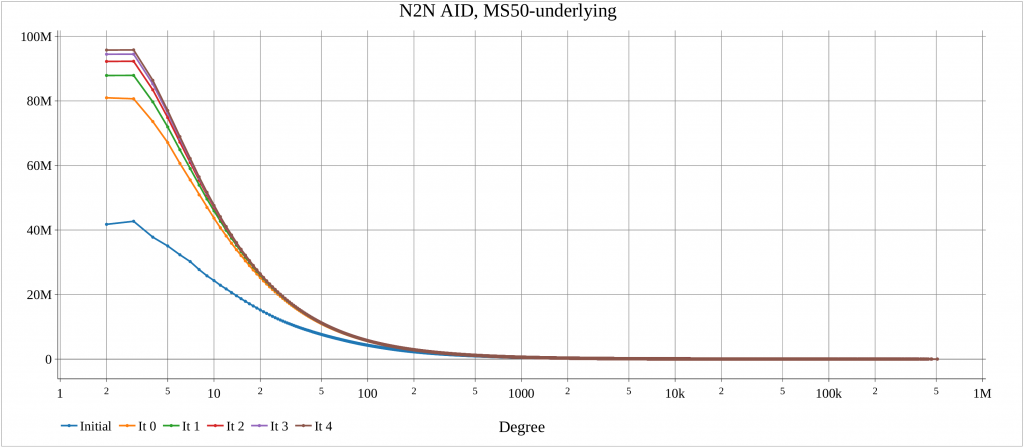
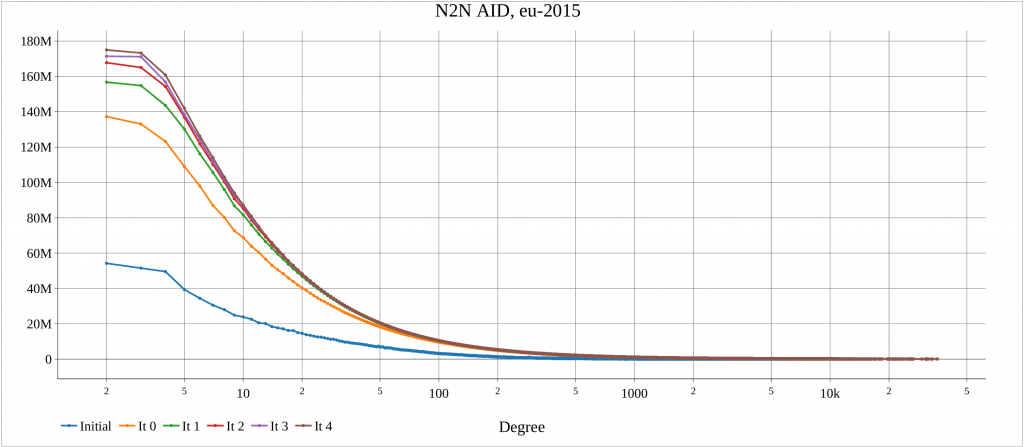
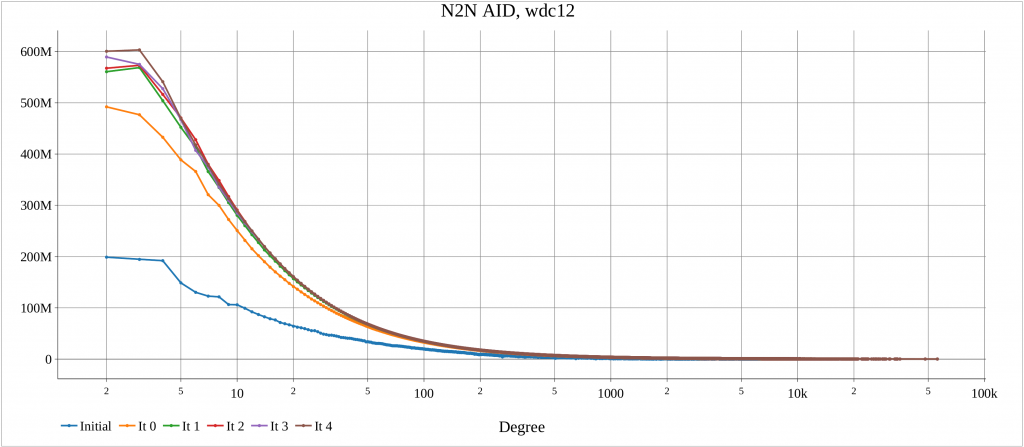
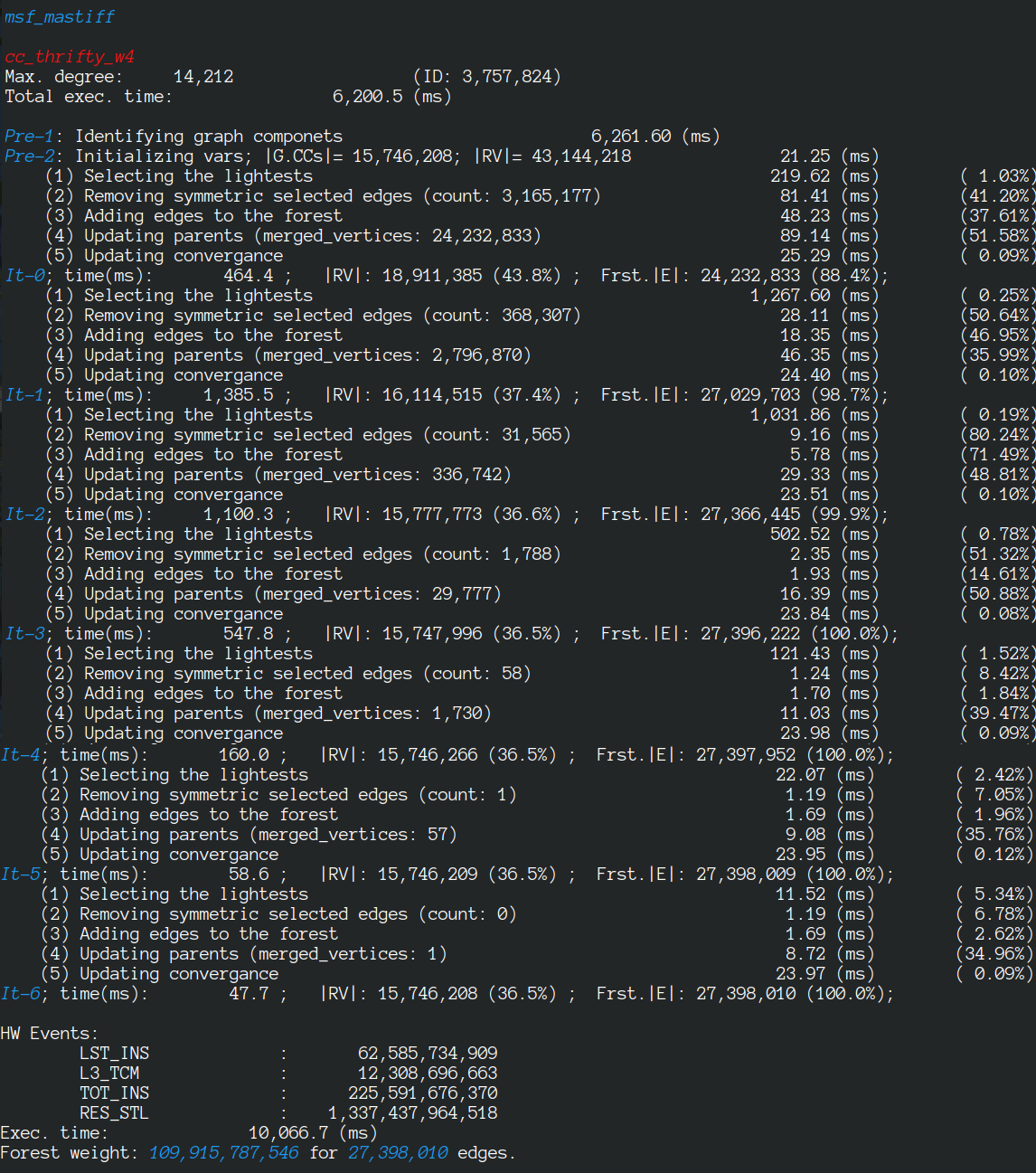
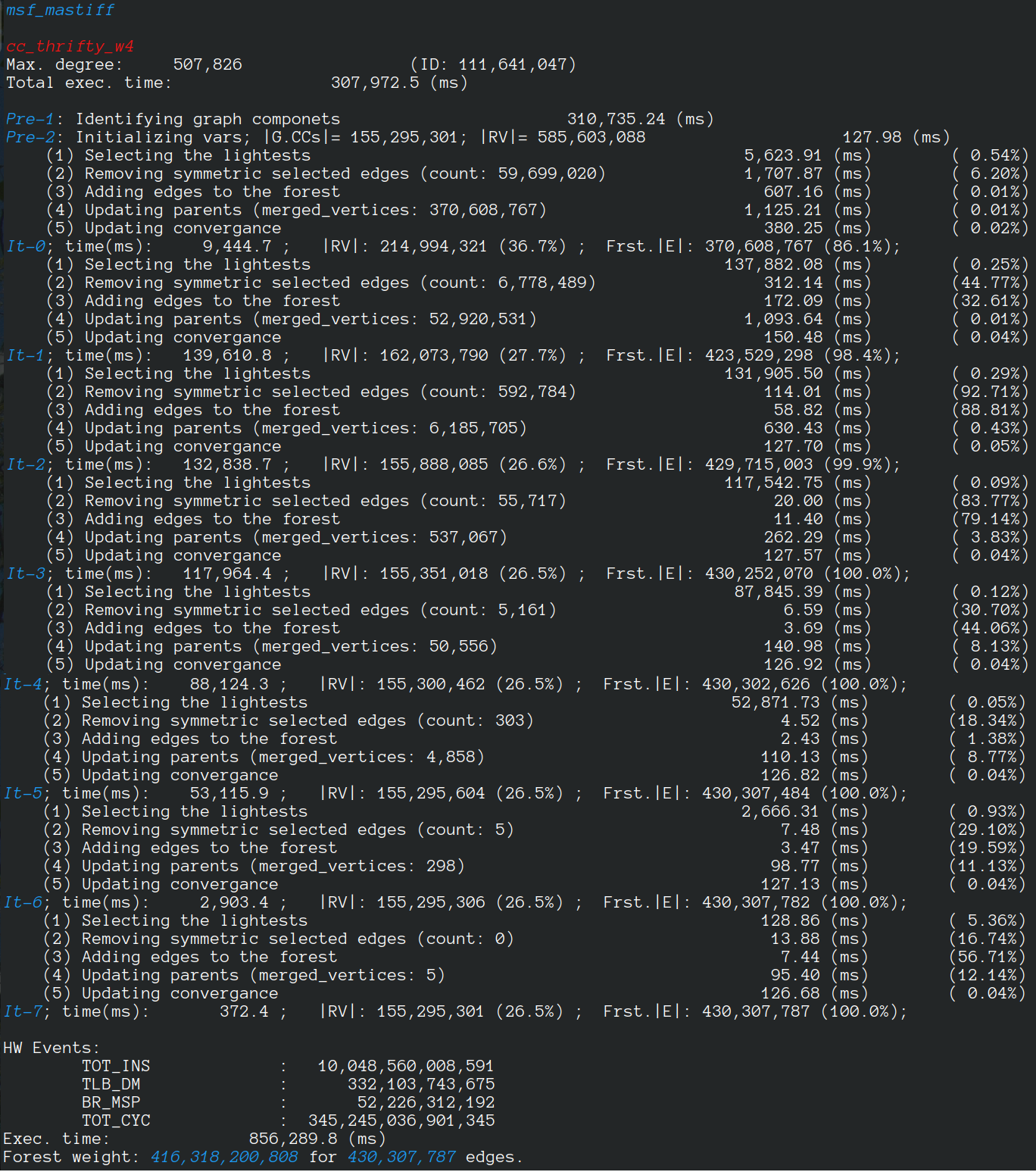
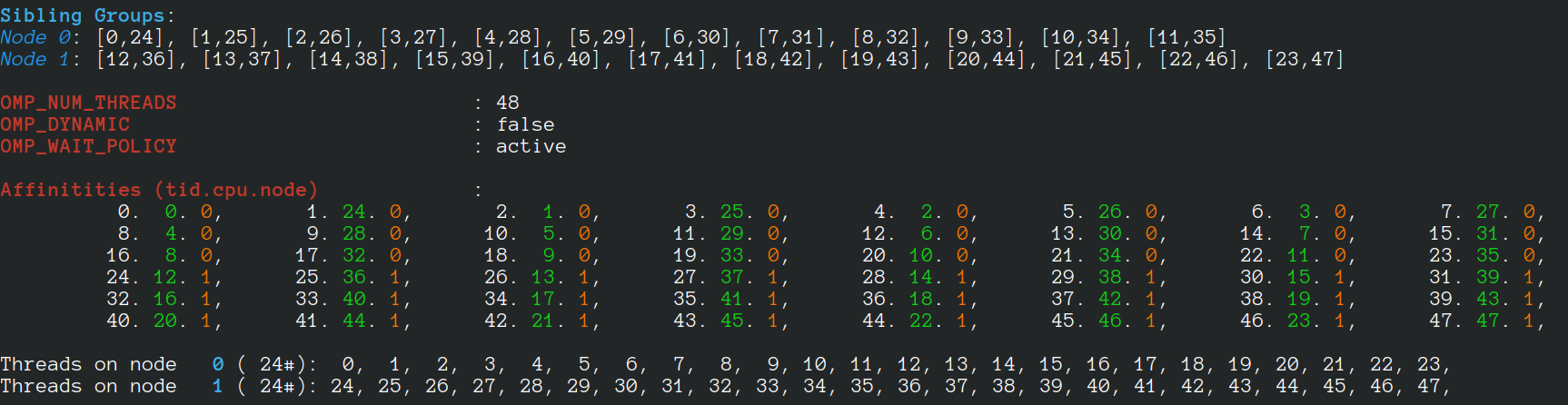
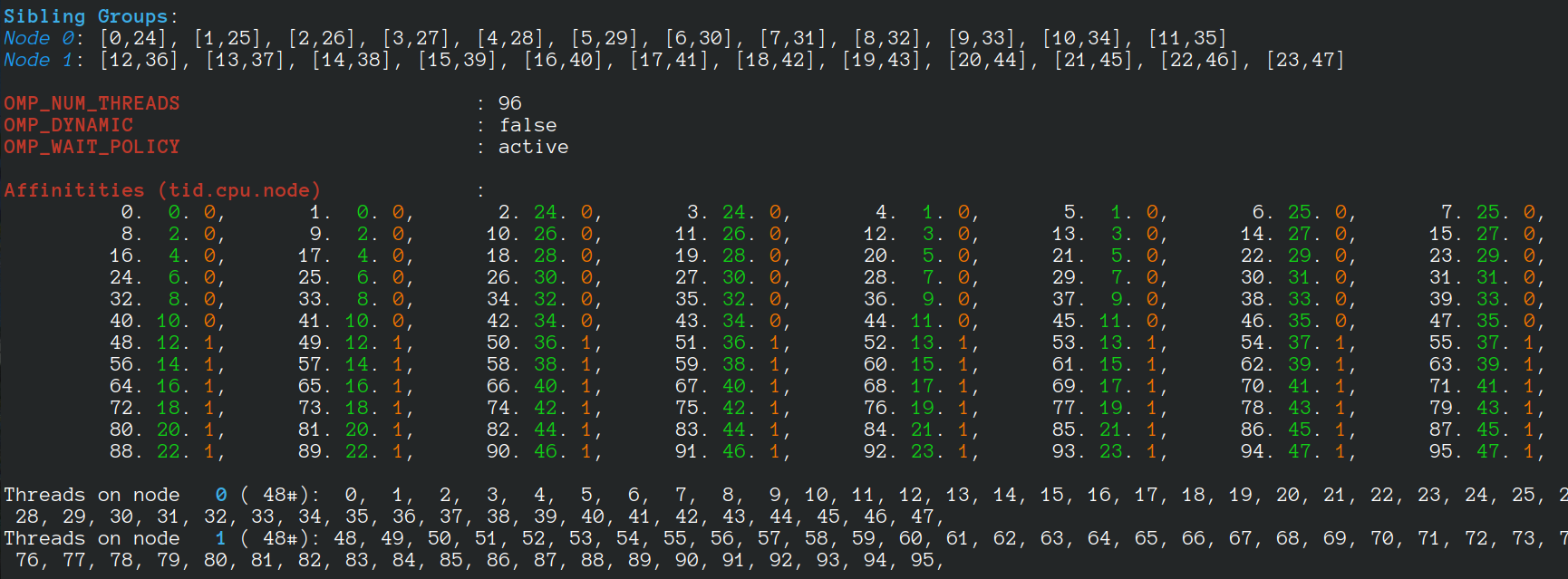
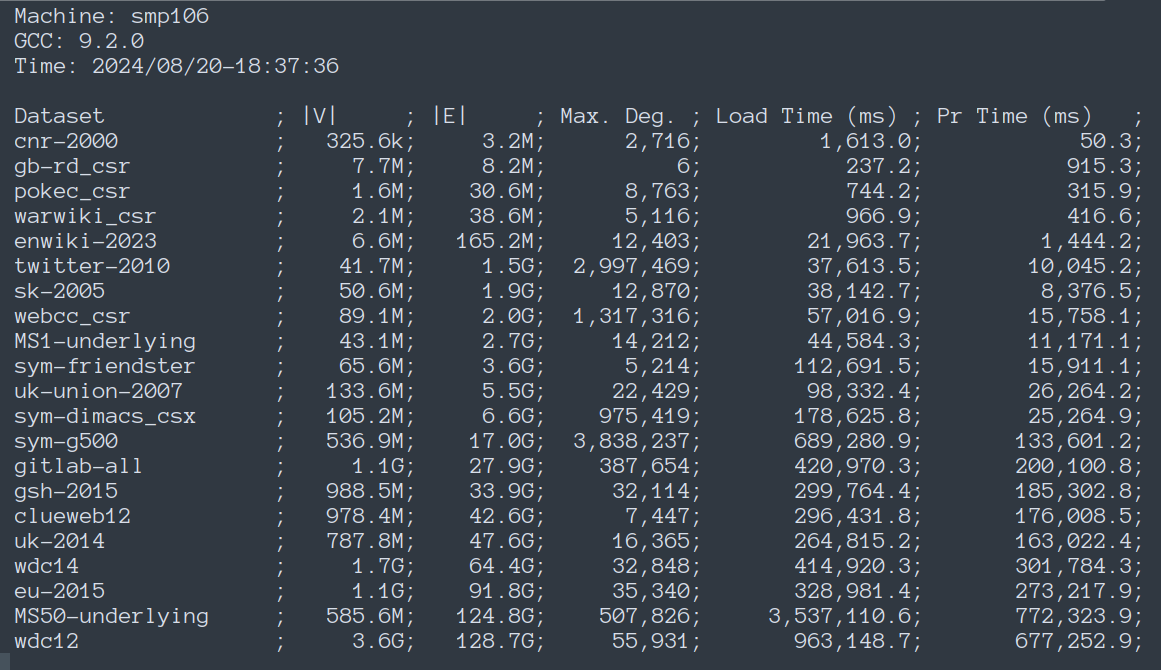
The algorithm has been executed on a machine with two AMD 7401 CPUs, 128 cores, 128 threads. The report created by the launcher is in the following.
- Random Vertex Relabelling in LaganLighter

- Minimum Spanning Forest of MS-BioGraphs

- Topology-Based Thread Affinity Setting (Thread Pinning) in OpenMP

- An (Incomplete) List of Publicly Available Graph Datasets/Generators

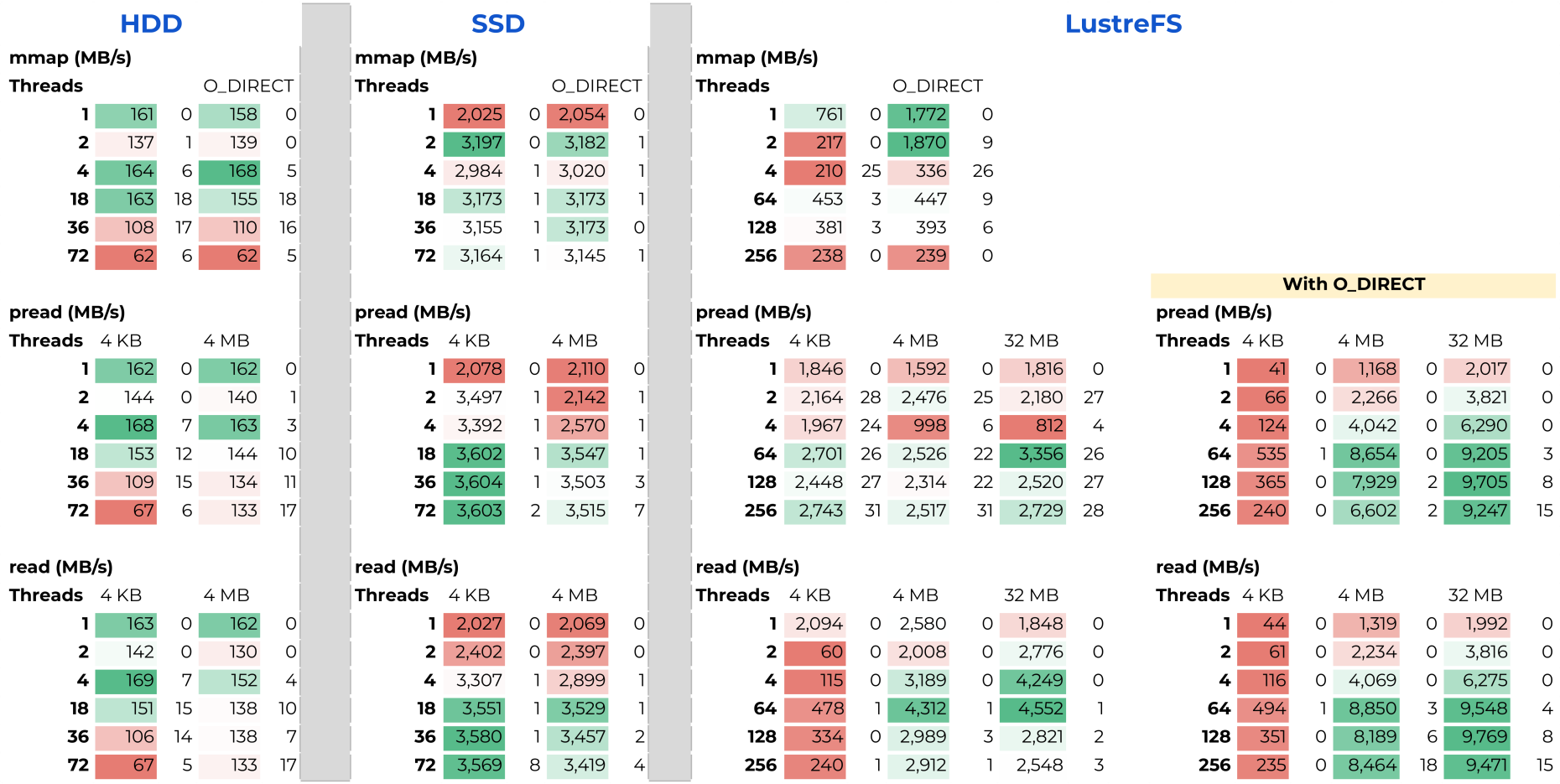
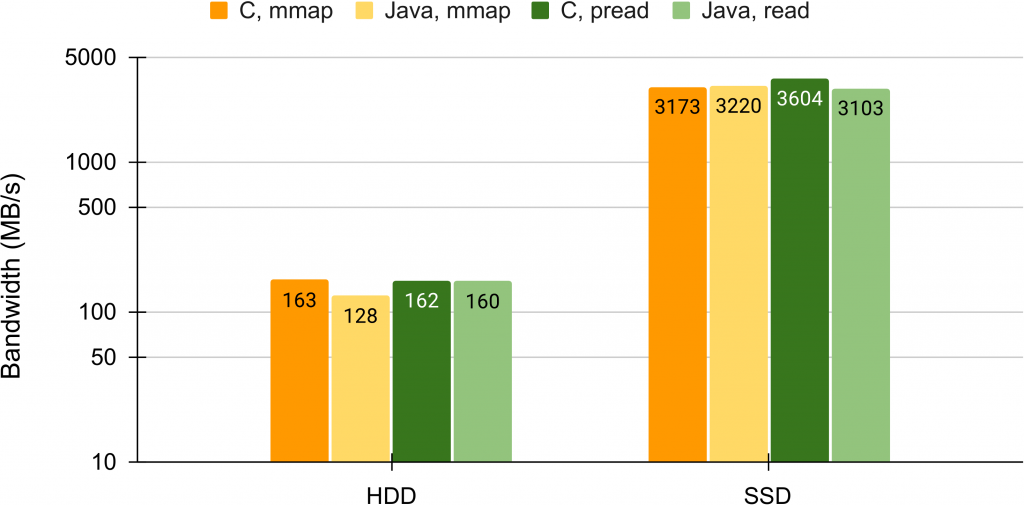
- An Evaluation of Bandwidth of Different Storage Types (HDD vs. SSD vs. LustreFS) for Different Block Sizes and Different Parallel Read Methods (mmap vs pread vs read)

- SIMD Bit Twiddling Hacks

- LaganLighter Source Code

- On Optimizing Locality of Graph Transposition on Modern Architectures

- Random Vertex Relabelling in LaganLighter
- Minimum Spanning Forest of MS-BioGraphs
- Topology-Based Thread Affinity Setting (Thread Pinning) in OpenMP
- ParaGrapher Integrated to LaganLighter

- On Designing Structure-Aware High-Performance Graph Algorithms (PhD Thesis)

- LaganLighter Source Code
- MASTIFF: Structure-Aware Minimum Spanning Tree/Forest – ICS’22

- SAPCo Sort: Optimizing Degree-Ordering for Power-Law Graphs – ISPASS’22 (Poster)

- LOTUS: Locality Optimizing Triangle Counting – PPOPP’22

- Locality Analysis of Graph Reordering Algorithms – IISWC’21

- Thrifty Label Propagation: Fast Connected Components for Skewed-Degree Graphs – IEEE CLUSTER’21

- Exploiting in-Hub Temporal Locality in SpMV-based Graph Processing – ICPP’21

- How Do Graph Relabeling Algorithms Improve Memory Locality? ISPASS’21 (Poster)