2021 IEEE International Symposium on Workload Characterization (IISWC’21)
November 7-9, 2021
Acceptance Rate: 39.5%
DOI: 10.1109/IISWC53511.2021.00020
Authors’ Copy (PDF Format)
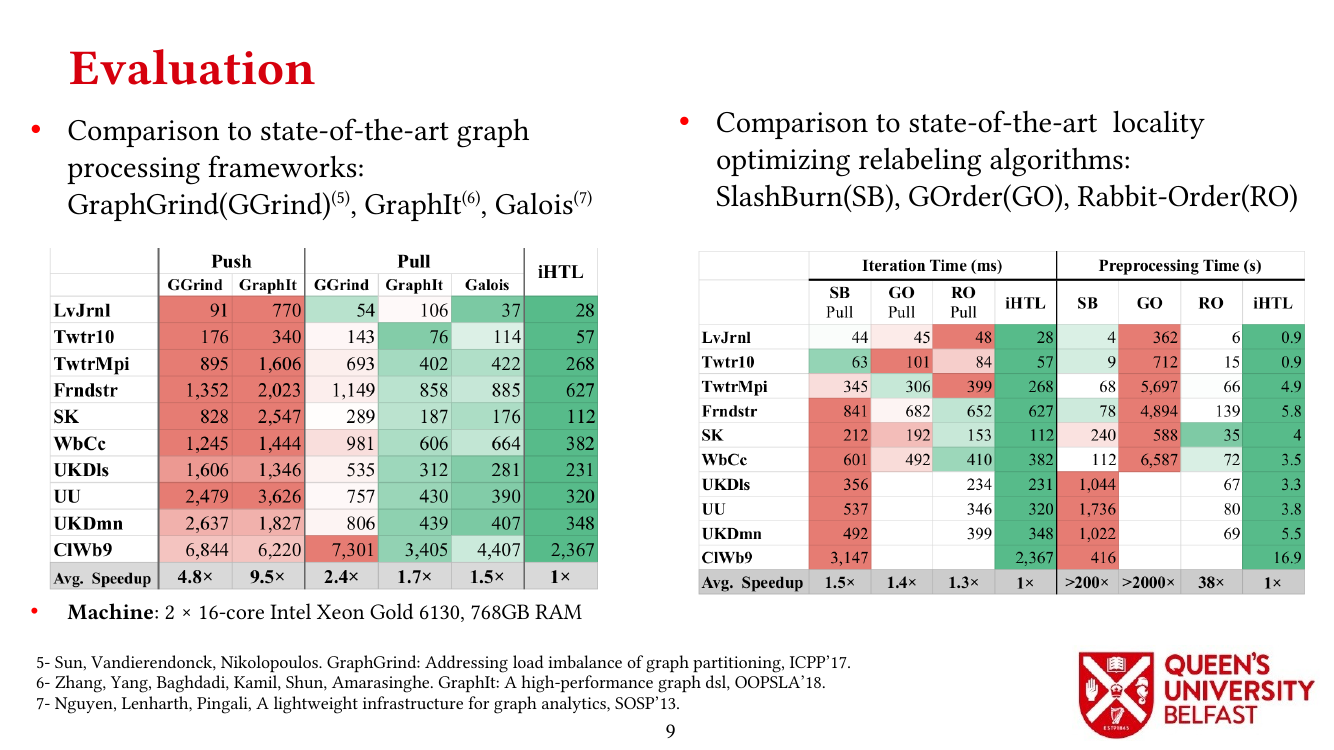
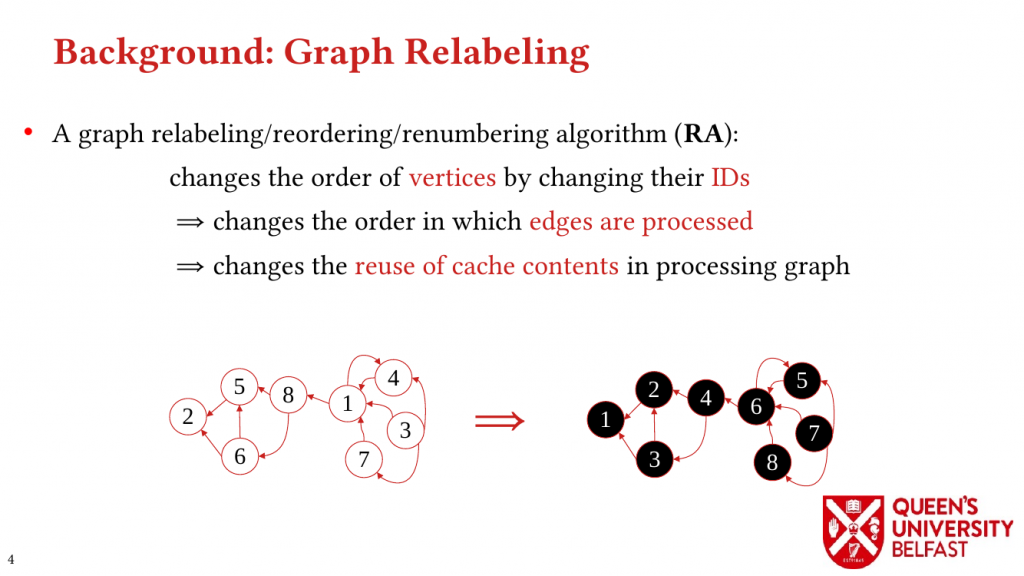
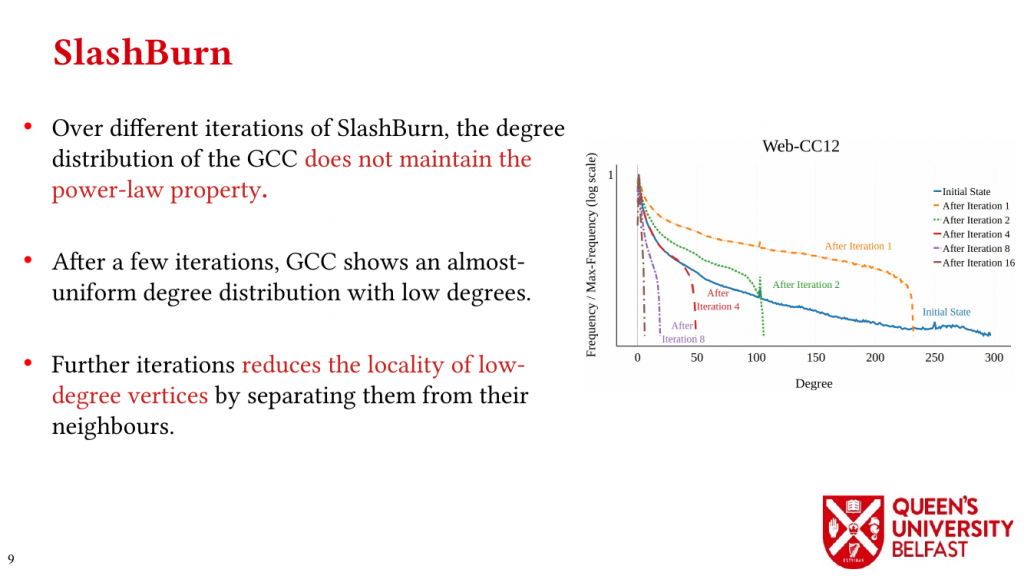
Graph reordering algorithms try to improve locality of graph algorithms by assigning new IDs to vertices that ultimately changes the order of random memory accesses. While graph relabeling algorithms such as SlashBurn, GOrder, and Rabbit-Order provide better locality, it is not clear how they affect graph processing and different graph datasets , mainly, for three reasons:
(1) The large size of datasets,
(2) The lack of suitable measurement tools, and
(3) Disparate characteristics of graphs.
The paucity of analysis has also inhibited the design of more efficient RAs.
This paper introduces a number of metrics and tools to investigate the functionality of graph reordering algorithms and their effects on different real-world graph datasets:
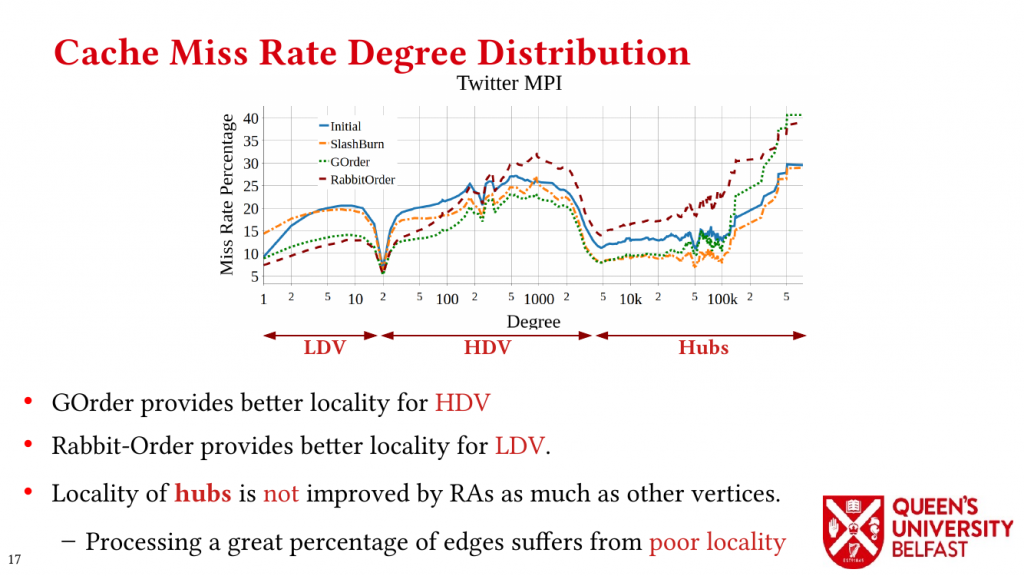
(1) We introduce the Cache Miss Rate Degree Distribution and Degree Distribution of Neighbour to Neighbour Average Distance ID (N2N AID) to show how reordering algorithms affect different vertices,
(2) We introduce the Effective Cache Size as a metric to measure how much of cache capacity is used by reordered graphs for satisfying random memory accesses,
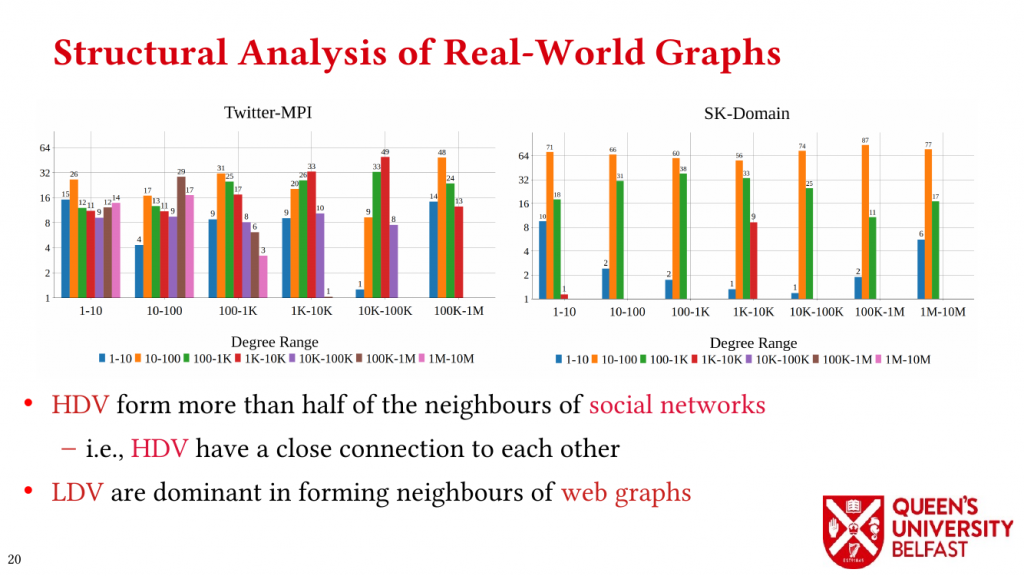
(3) We introduce the Assymetricity Degree Distribution and Neighbourhood Decomposition to explain the composition of neighbourhood of vertices to explain structural differences between web graphs and social networks.
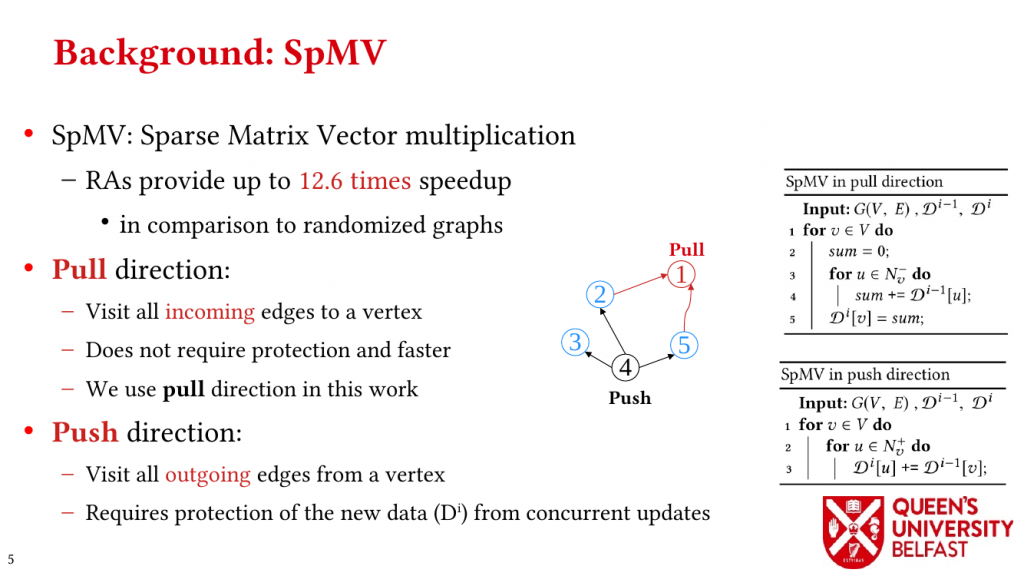
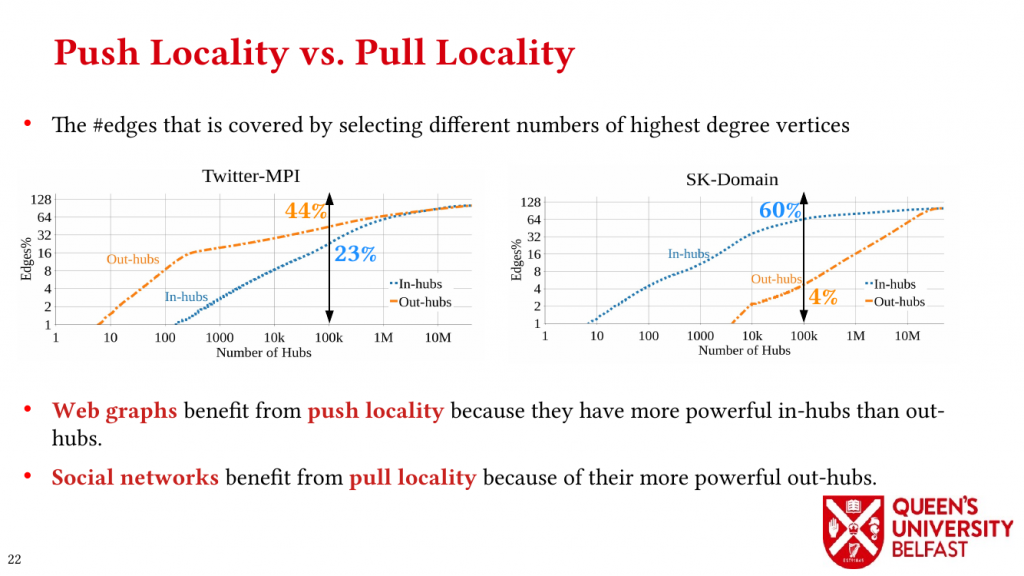
(4) We investigate the effects of the structure of real-world graphs on the locality and performance of traversing graphs in pull and push directions by introducing Push Locality and Pull Locality.
Finally, we present improvements to graph reordering algorithms and propose other suggestions based on the new insights and features of real-world graphs introduced by this paper.


















BibTex
@INPROCEEDINGS{10.1109/IISWC53511.2021.00020,
author={Koohi Esfahani, Mohsen and Kilpatrick, Peter and Vandierendonck, Hans},
booktitle={2021 IEEE International Symposium on Workload Characterization (IISWC'21)},
title={Locality Analysis of Graph Reordering Algorithms},
year={2021},
volume={},
number={},
pages={101-112},
publisher={IEEE Computer Society},
doi={10.1109/IISWC53511.2021.00020}
}
Related Posts
- On Optimizing Locality of Graph Transposition on Modern Architectures

- Random Vertex Relabelling in LaganLighter

- Minimum Spanning Forest of MS-BioGraphs

- Topology-Based Thread Affinity Setting (Thread Pinning) in OpenMP

- ParaGrapher Integrated to LaganLighter

- On Designing Structure-Aware High-Performance Graph Algorithms (PhD Thesis)

- LaganLighter Source Code

- MASTIFF: Structure-Aware Minimum Spanning Tree/Forest – ICS’22

- SAPCo Sort: Optimizing Degree-Ordering for Power-Law Graphs – ISPASS’22 (Poster)

- LOTUS: Locality Optimizing Triangle Counting – PPOPP’22

- Locality Analysis of Graph Reordering Algorithms – IISWC’21

- Thrifty Label Propagation: Fast Connected Components for Skewed-Degree Graphs – IEEE CLUSTER’21

- Exploiting in-Hub Temporal Locality in SpMV-based Graph Processing – ICPP’21

- How Do Graph Relabeling Algorithms Improve Memory Locality? ISPASS’21 (Poster)