
Repository
https://github.com/DIPSA-QUB/LaganLighter
Documentation
https://github.com/DIPS-QUB/LaganLighter/tree/main/docs
Algorithms in This Repo
- SAPCo Sort:
alg1_sapco_sort - Thrifty Label Propagation Connected Components:
alg2_thrifty - MASTIFF: Structure-Aware Mimum Spanning Tree/Forest:
alg3_mastiff - iHTL: in-Hub Temporal Locality in SpMV (Sparse-Matrix Vector Multiplication) based Graph Processing: (to be added)
- LOTUS: Locality Optimizing Trinagle Counting: (to be added)
Cloning
git clone https://github.com/MohsenKoohi/LaganLighter.git --recursive
Graph Types
LaganLighter supports the following graph formats:
- CSR/CSC graph in text format, for testing. This format has 4 lines: (i) number of vertices (|V|), (ii) number of edges (|E|), (iii) |V| space-separated numbers showing offsets of the vertices, and (iv) |E| space-separated numbers indicating edges.
- CSR/CSC WebGraph format: supported by the Poplar Graph Loading Library
external git repository
Measurements
In addition to execution time, we use the PAPI library to measure hardware counters such as L3 cache misses, hardware instructions, DTLB misses, and load and store memory instructions. ( papi_(init/start/reset/stop) and (print/reset)_hw_events functions defined in omp.c).
To measure load balance, we measure the total time of executing a loop and the time each thread spends in this loop (mt and ttimes in the following sample code). Using these values, PTIP macro (defined in omp.c) calculates the percentage of average idle time (as an indicator of load imbalance) and prints it with the total time (mt).
mt = - get_nano_time()
#pragma omp parallel
{
unsigned tid = omp_get_thread_num();
ttimes[tid] = - get_nano_time();
#pragma omp for nowait
for(unsigned int v = 0; v < g->vertices_count; v++)
{
// .....
}
ttimes[tid] += get_nano_time();
}
mt += get_nano_time();
PTIP("Step ... ");
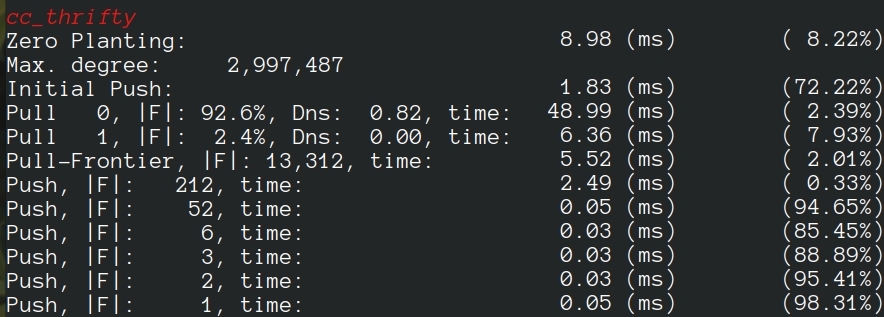
As an example, the following execution of Thrifty, shows that the “Zero Planting” step has been performed in 8.98 milliseconds and with a 8.22% load imbalance, while processors have been idle for 72.22% of the execution time, on average, in the “Initial Push” step.
NUMA-Aware and Locality-Preserving Partitioning and Scheduling
In order to assign consecutive partitions (vertices and/or their edges) to each parallel processor, we initially divide partitions and assign a number of consecutive partitions to each thread. Then, we specify the order of victim threads in the work-stealing process. During the initialization of LaganLighter parallel processing environment (in initialize_omp_par_env() function defined in file omp.c), for each thread, we create a list of threads as consequent victims of stealing.
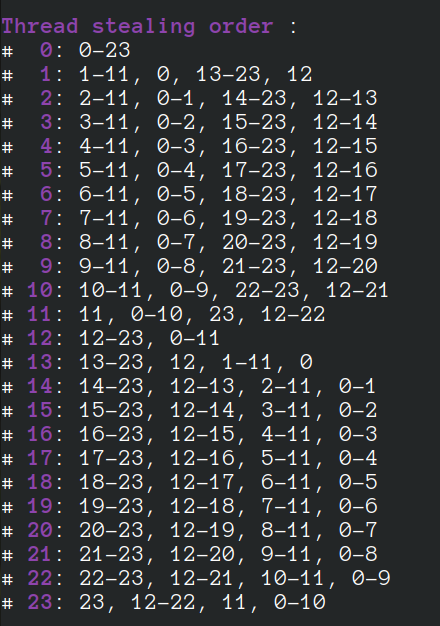
A thread, first, steals jobs (i.e., partitions) from consequent threads in the same NUMA node and then from the threads in consequent NUMA nodes. As an example, the following image shows the stealing order of a 24-core machine with 2 NUMA nodes. This shows that thread 1 steals from threads 2, 3, …,11, and ,0 running on the same NUMA socket and then from threads 13, 14, …, 23, and 12 running on the next NUMA socket.
We use dynamic_partitioning_...() functions (in file partitioning.c) to process partitions by threads in the specified order. A sample code is in the following:
struct dynamic_partitioning* dp = dynamic_partitioning_initialize(pe, partitions_count);
#pragma omp parallel
{
unsigned int tid = omp_get_thread_num();
unsigned int partition = -1U;
while(1)
{
partition = dynamic_partitioning_get_next_partition(dp, tid, partition);
if(partition == -1U)
break;
for(v = start_vertex[partition]; v < start_vertex[partition + 1]; v++)
{
// ....
}
}
}
dynamic_partitioning_reset(dp);
Bugs & Support
As “we write bugs that in particular cases have been tested to work correctly”, we try to evaluate and validate the algorithms and their implementations. If you receive wrong results or you are suspicious about parts of the code, please contact us or submit an issue.
License
Licensed under the GNU v3 General Public License, as published by the Free Software Foundation. You must not use this Software except in compliance with the terms of the License. Unless required by applicable law or agreed upon in writing, this Software is distributed on an “as is” basis, without any warranty; without even the implied warranty of merchantability or fitness for a particular purpose, neither express nor implied. For details see terms of the License.
Copyright 2022 The Queen’s University of Belfast, Northern Ireland, UK
Related Posts
- On Optimizing Locality of Graph Transposition on Modern Architectures

- Random Vertex Relabelling in LaganLighter
- Minimum Spanning Forest of MS-BioGraphs
- Topology-Based Thread Affinity Setting (Thread Pinning) in OpenMP
- ParaGrapher Integrated to LaganLighter
- On Designing Structure-Aware High-Performance Graph Algorithms (PhD Thesis)
- LaganLighter Source Code
- MASTIFF: Structure-Aware Minimum Spanning Tree/Forest – ICS’22
- SAPCo Sort: Optimizing Degree-Ordering for Power-Law Graphs – ISPASS’22 (Poster)
- LOTUS: Locality Optimizing Triangle Counting – PPOPP’22
- Locality Analysis of Graph Reordering Algorithms – IISWC’21
- Thrifty Label Propagation: Fast Connected Components for Skewed-Degree Graphs – IEEE CLUSTER’21
- Exploiting in-Hub Temporal Locality in SpMV-based Graph Processing – ICPP’21
- How Do Graph Relabeling Algorithms Improve Memory Locality? ISPASS’21 (Poster)














- Random Vertex Relabelling in LaganLighter
- Minimum Spanning Forest of MS-BioGraphs
- Topology-Based Thread Affinity Setting (Thread Pinning) in OpenMP
- An (Incomplete) List of Publicly Available Graph Datasets/Generators
- An Evaluation of Bandwidth of Different Storage Types (HDD vs. SSD vs. LustreFS) for Different Block Sizes and Different Parallel Read Methods (mmap vs pread vs read)
- SIMD Bit Twiddling Hacks
- LaganLighter Source Code






