
Short URL of this post: https://blogs.qub.ac.uk/DIPSA/HDD-vs-SSD-vs-LustreFS-2024
We evaluate read bandwidth of three storage types:
- HDD: A 6TB Hitachi HUS726060AL 7200RPM SATA v3.1
- SSD: A 4TB Samsung MZQL23T8HCLS-00A07 PCIe4 NVMe v1.4
- LustreFS: A parallel file system with total 2PB with a SSD pool
and for three parallel read methods:
- mmap: https://man7.org/linux/man-pages/man2/mmap.2.html
- pread: https://man7.org/linux/man-pages/man2/pread.2.html
- read: https://man7.org/linux/man-pages/man2/read.2.html
and for two block sizes:
- 4 KB blocks
- 4 MB blocks
The source code is available on ParaGrapher repository:
- https://github.com/DIPSA-QUB/ParaGrapher/blob/main/test/read_bandwidth.c
- https://github.com/DIPSA-QUB/ParaGrapher/blob/main/test/read_bandwidth_mam.c : this file is similar to previous one, but repeats each evaluation for a user-defined number of rounds and identifies Min, Average, and Max. values.
The OS cache of storage contents have been dropped after each evaluation
(sudo sh -c 'echo 3 >/proc/sys/vm/drop_caches').
The flushcache.c file (https://github.com/DIPSA-QUB/ParaGrapher/blob/main/test/flushcache.c) can be used with the same functionality for users without sudo access, however, it usually takes more time to be finished.
For LustreFS, we have repeated the evaluation of read and pread using O_DIRECT flag as this flag prevents client-side caching.
For HDD and SSD experiments, we have used a machine with Intel W-2295 3.00GHz CPU, 18 cores, 36 hyper-threads, 24MB L3 cache, 256 GB DDR4 2933Mhz memory, running Debian 12 Linux 6.1. For LustreFS, we have used a machine with 2TB 3.2GHz DDR4 memory, 2 AMD 7702 CPUs, in total, 128 cores, 256 threads.
The results of the evaluation using read_bandwidth.c are in the following table. The values are Bandwidth in MB/s. Also, 1-2 digits close to each number with a white background are are percentage of load imbalance between parallel threads.
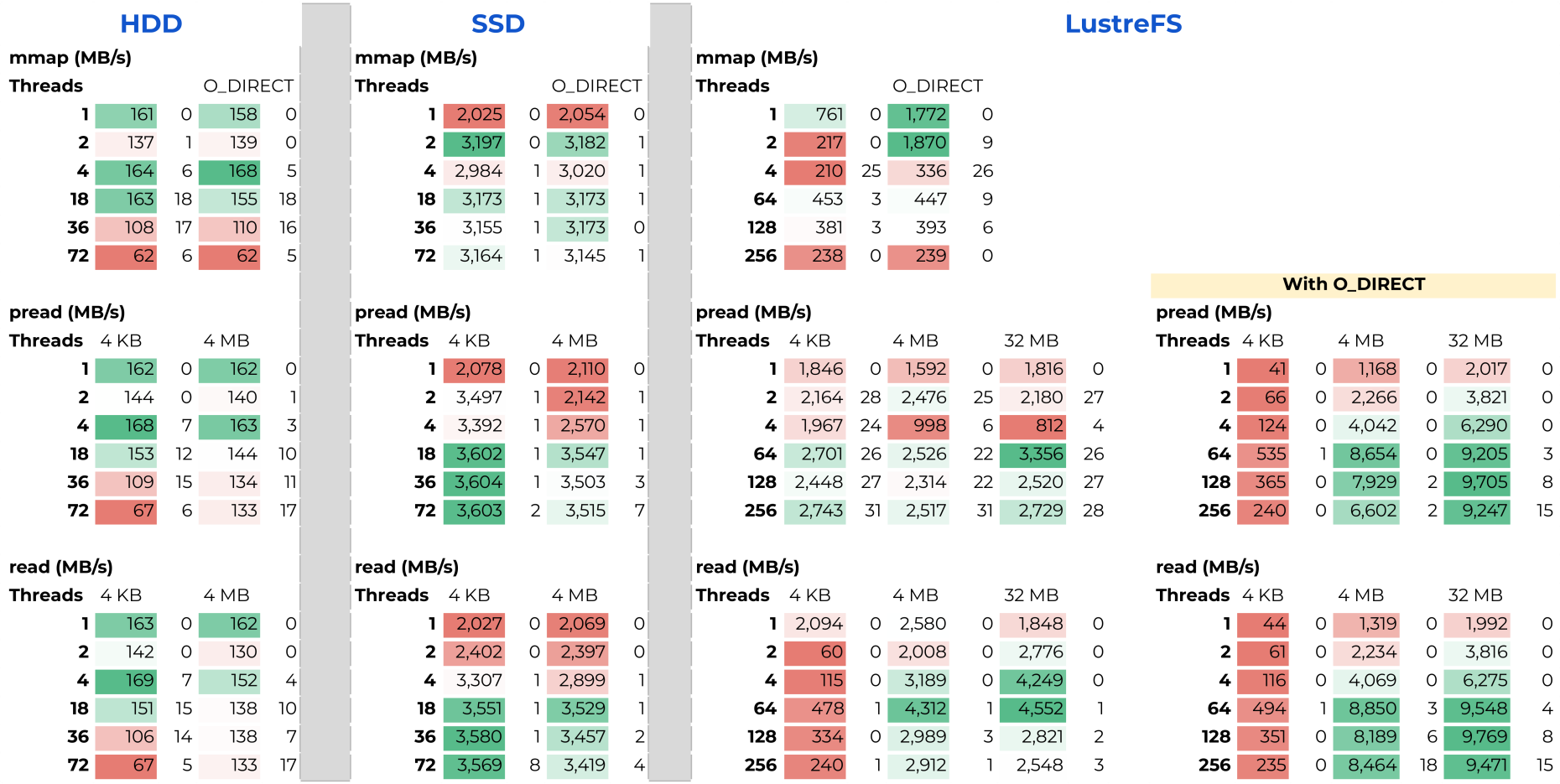
Please click on the image to expand.
C vs. Java
We measure the bandwidth of SSD and HDD in C (mmap and pread) vs. Java (mmap and read). We use a machine with Intel W-2295 3.00GHz CPU, 18 cores, 36 hyper-threads, 24MB L3 cache, 256 GB DDR4 2933Mhz memory, running Debian 12 Linux 6.1 and the following codes:
- https://github.com/DIPSA-QUB/ParaGrapher/blob/main/test/read_bandwidth.c
- https://github.com/DIPSA-QUB/ParaGrapher/blob/main/test/ReadBandwidth.java : this is a Java-based evaluation of read bandwidth and the script (https://github.com/DIPSA-QUB/ParaGrapher/blob/main/test/java-read-bandwidth.sh) can be used to create changes in evaluation parameters.
The results are in the following.
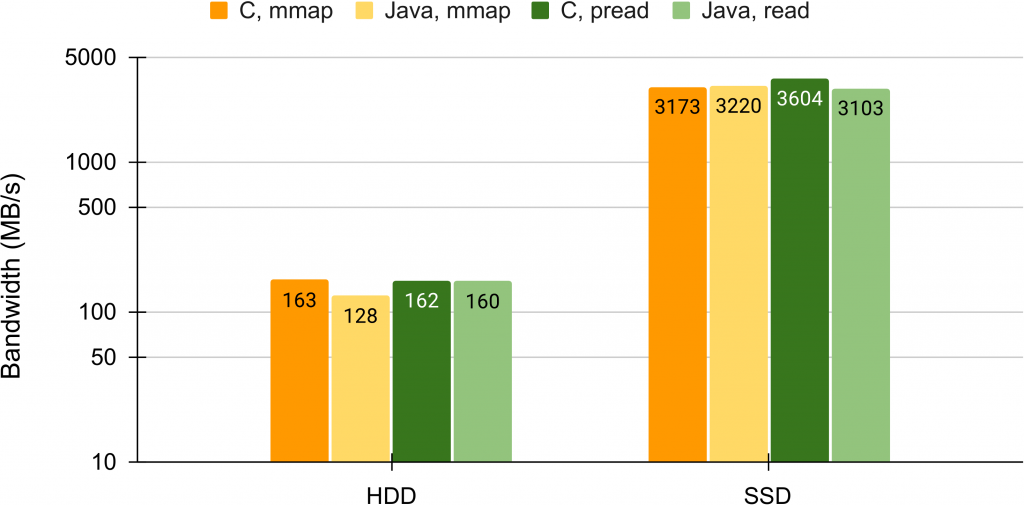
For similar comparisons you may refer to:
– https://github.com/david-slatinek/c-read-vs.-mmap/tree/main
– https://eklausmeier.goip.de/blog/2016/02-03-performance-comparison-mmap-versus-read-versus-fread/
- Random Vertex Relabelling in LaganLighter

- Minimum Spanning Forest of MS-BioGraphs

- Topology-Based Thread Affinity Setting (Thread Pinning) in OpenMP

- An (Incomplete) List of Publicly Available Graph Datasets/Generators

- An Evaluation of Bandwidth of Different Storage Types (HDD vs. SSD vs. LustreFS) for Different Block Sizes and Different Parallel Read Methods (mmap vs pread vs read)

- SIMD Bit Twiddling Hacks

- LaganLighter Source Code

- ParaGrapher: A Parallel and Distributed Graph Loading Library for Large-Scale Compressed Graphs – BigData’25 (Short Paper)

- Accelerating Loading WebGraphs in ParaGrapher

- Selective Parallel Loading of Large-Scale Compressed Graphs with ParaGrapher – arXiv Version

- An Evaluation of Bandwidth of Different Storage Types (HDD vs. SSD vs. LustreFS) for Different Block Sizes and Different Parallel Read Methods (mmap vs pread vs read)
- ParaGrapher Integrated to LaganLighter

- ParaGrapher Source Code For WebGraph Types




