
Scheduling or distributing the computational workload over multiple threads is a critical and repeatedly performed activity in graph processing workloads. In a recent paper “Reducing the burden of parallel loop schedulers for many‐core processors” published in Concurrency & Computation: Practice & Experience, we investigated the overhead introduced by scheduling. This overhead follows from two effects: (i) threads require to communicate and arrive at the same point in the program at the same time; (ii) inter-thread communication incurs significant cache misses and coherence messages sent between processors. We have likened the work distribution to barrier synchronisation and observed that state-of-the-art parallel schedulers such as the Intel OpenMP runtime and Intel Cilkplus incur the cost of a full-barrier synchronisation at the start of a parallel loop and at the end of the loop. The below figure illustrates the synchronisation pattern:
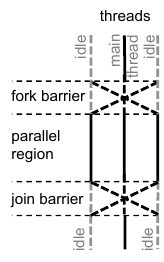
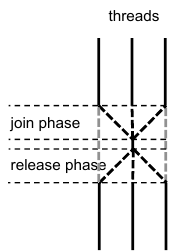
A barrier synchronisation is a synchronisation mechanism that waits for all threads to arrive at the barrier, then signals each thread they may continue execution. If we look in more detail at a barrier, it consists of two phases: a join phase and a release phase:
However, this introduces redundant synchronisation. It suffices to place only a half-barrier synchronisation at the start of the loop, and the other half at the end of the loop. Schematically, this looks like this:
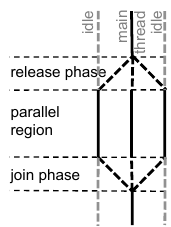
Based on this observation, we designed an optimised scheduling technique that works specifically well for fine-grain loops, which are typically counted loops with very short loop bodies.
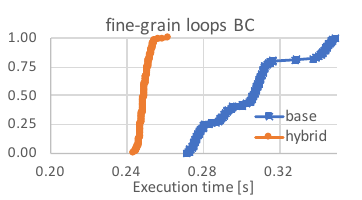
Using our optimised scheduler, fine-grain loops in graph processing applications can be sped up by 21.6% to 29.6%. The below figure shows a histogram of the performance obtained for the fine-grain loops in the betweenness centrality kernel (BC). This evaluation was performed on a four-socket 2.6 GHz Intel Xeon E7-4860 v2 machine with 12 physical cores per socket (plus hyperthreading) and30 MB L3 cache per socket. The baseline uses the Intel Cilkplus scheduler, while hybrid demonstrates performance of a hybrid version of the Cilkplus scheduler which can execute a mixture of coarse-grain loops (scheduled using the normal Cilkplus policy) and fine-grain loops using our optimised scheduler.
As graph processing applications contain a mix of fine-grain and coarse-grain loop, overall speedups in these applications is below 5%.
More details can be found in the paper, published under Open Access: https://onlinelibrary.wiley.com/doi/10.1002/cpe.6241